1. Introduction to Jdbi 3
Jdbi provides convenient, idiomatic, access to relational data in Java. Jdbi 3 is the third major release, which introduces enhanced support for modern Java, countless refinements to the design and implementation, and enhanced support for modular development through plugins and extensions.
Jdbi is built on top of JDBC. If your data source has a JDBC driver, you can use it with Jdbi. It improves JDBC’s low-level interface, providing a more natural API that is easy to bind to your domain data types.
Jdbi is not an ORM. It is a convenience library to make Java database operations simpler and more pleasant to program than raw JDBC. While there is some ORM-like functionality, Jdbi goes to great length to ensure that there is no hidden magic that makes it hard to understand what is going on.
Jdbi does not hide SQL away. One of the design principles of Jdbi is that SQL is the native language of the database, and it is unnecessary to wrap it into code, deconstruct it, or hide it away. Being able to express a query in raw SQL makes it possible for programmers and data engineers to speak the same language and not fight translation layers.
Jdbi does not aim to provide a complete database management framework. It provides the building blocks that allow constructing the mapping between data and objects as appropriate for your application and the necessary primitives to execute SQL code against your database.
1.2. Getting involved
Jdbi uses GitHub as the central development hub. Issues, Pull Requests and Discussions all happen here.
Please see our Contribution guide for more information on how to contribute to Jdbi.
1.3. JDBI v2 (legacy version)
| JDBI v2 is no longer under active development! |
| Already using Jdbi v2? See Upgrading from v2 to v3 |
2. Using Jdbi in your projects
2.1. License, Dependencies and availability
Jdbi is licensed under the commercial friendly Apache 2.0 license.
The core Jdbi module which offers programmatic access uses only slf4j and geantryref as hard dependencies.
All Jdbi modules are available through Maven Central. Jdbi also offers a BOM (Bill of materials) module for easy dependency management.
2.2. JVM version compatibility
Jdbi runs on all Java versions 11 or later. All releases are built with the latest LTS version of Java using Java 11 bytecode compatibility.
| Jdbi ended support for Java 8 with version 3.39. There are occasional backports of security relevant things or major bugs but as of version 3.40.0, JDK 11+ is required. |
2.3. Getting started
Jdbi has a flexible plugin architecture, which makes it easy to fold in support for your favorite libraries (Guava, JodaTime, Spring, Vavr) or database vendors (Oracle, Postgres, H2).
Jdbi is not an ORM. There is no session cache, change tracking, "open session in view", or cajoling the library to understand your schema.
Jdbi provides straightforward mapping between SQL and data accessible through a JDBC driver. You bring your own SQL, and Jdbi executes it.
Jdbi provides several other modules, which enhance the core API with additional features.
2.3.1. Jdbi modules overview
Jdbi consists of a large number of modules. Not all are required when writing database code. This is a quick overview of the existing modules and their function:
Common modules
- jdbi3-core
-
The core Jdbi library. Required by all other components.
- jdbi3-sqlobject
-
SQL Object extension for declarative database access.
Testing support
- jdbi3-testing
-
Testing framework support. Currently, only supports JUnit4 and JUnit5.
- jdbi3-testcontainers
-
Support for arbitrary databases running in Testcontainers. Currently, only supports JUnit 5.
External data types and libraries
The core module contains support for the Immutables and Freebuilder libraries.
- jdbi3-guava
-
Support for Google Guava collection and Optional types.
- jdbi3-jodatime2
-
Support for JodaTime v2 data types.
- jdbi3-vavr
-
Support for Vavr Tuples, Collections and Value arguments.
JSON Mapping
Support for various JSON libraries to map data from the database onto JSON types and vice versa.
- jdbi3-jackson2
-
Support for Jackson v2.
- jdbi3-gson
-
Support for Google Gson.
- jdbi3-moshi
-
Support for Square Moshi.
Frameworks
- jdbi3-guice
-
Support dependency injection and modules with Google Guice.
- jdbi3-spring5
-
Provides a Spring Framework factory bean to set up Jdbi singleton.
- jdbi3-jpa
-
Some support for JPA annotations.
Database specific types and functions
While Jdbi supports any data source that has a JDBC driver "out of the box", its support is limited to the standard JDBC types and mappings. Some databases have additional data types and mappings, and support is added using the following modules:
| While Oracle support is considered part of Jdbi, the actual library is developed and shipped as a separate component for historic reasons. |
SQL rendering
SQL statements can be rendered before they are sent to the database driver. Unless explicitly configured, Jdbi uses a simple render engine that replaces <…> placeholders. It is possible to replace this engine with other template engines.
- jdbi3-stringtemplate4
-
Use the StringTemplate 4 template engine to render SQL statements.
- jdbi3-commons-text
-
Use Apache Commons Text to render SQL statements.
- jdbi3-freemarker
-
Use Apache Freemarker to render SQL statements.
Cache support
- jdbi3-caffeine-cache
-
Use the Caffeine caching library for SQL template and parse caching.
- jdbi3-noop-cache
-
Turn off SQL template and parse caching for testing and debugging.
- jdbi3-guava-cache
-
Use the Guava Cache caching library for SQL template and parse caching.
| The guava caching module is considered experimental. |
Additional Language support
Jdbi can be used from any language and technology running on the JVM that can use Java code (Kotlin, Scala, Clojure, JRuby etc).
While Java is a first class citizen (and will be for the foreseeable future), we provide modules for some languages that allow more idiomatic access to Jdbi functionality.
- jdbi3-kotlin
-
Automatically map Kotlin data classes.
- jdbi3-kotlin-sqlobject
-
Kotlin support for the SQL Object extension.
2.3.2. External modules
The following modules are maintained outside the main Jdbi tree:
| Module | Source | Javadoc | Site | Description |
|---|---|---|---|---|
jdbi3-oracle12 |
Support for Oracle 12 and beyond. |
|||
jdbi3-guava-cache |
Experimental support for the Guava cache library. |
| The additional modules are usually released in sync with the main release. If any of the links above for a release version do not resolve, it may be possible that a release was omitted by accident. In that case, please file an issue on the Bug Tracker. |
2.3.3. Build tools
All Jdbi modules are available through Maven Central, so any project that uses a dependency management tool (Apache Maven, Gradle, sbt, leiningen, Apache Ivy etc.) can access these.
For Apache Maven:
<dependencies>
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-core</artifactId>
<version>3.41.2</version>
</dependency>
</dependencies>For Gradle:
dependencies {
implementation("org.jdbi:jdbi3-core:3.41.2")
}When using multiple Jdbi modules, it is important that all modules use the same version. There is no guarantee that mixing versions will work.
Jdbi offers a BOM (Bill of Materials) that can be used to provide a consistent version for all Jdbi components.
For Apache Maven:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-bom</artifactId>
<type>pom</type>
<version>3.41.2</version>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>adds the Jdbi BOM module into the dependencyManagement section.
Jdbi components in use are declared in the <dependencies> section without a version:
<dependencies>
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-core</artifactId>
</dependency>
</dependencies>For Gradle:
dependencies {
// Load bill of materials (BOM) for Jdbi.
implementation(platform("org.jdbi:jdbi3-bom:3.41.2"))
}adds the BOM as dependency constraints to Gradle.
Jdbi components are declared without versions:
dependencies {
implementation("org.jdbi:jdbi3-core")
}2.3.4. @Alpha and @Beta Annotations
The @Alpha and @Beta annotations mark APIs as unstable. Each of these annotations signifies that a public API (public class, method or field) is subject to incompatible changes, or even removal, in a future release. Any API bearing these annotations is exempt from any compatibility guarantees.
-
Alpha— Alpha APIs are intended as early preview of features that might eventually get promoted. -
Beta— It is generally safe for applications to depend on beta APIs, at the cost of some extra work during upgrades. However, libraries (which get included on an application classpath) should not depend on Beta APIs as the classpath is outside the control of the library.
Note that the presence of this annotation implies nothing about the quality or performance of the API in question, only the fact that it is not "API-frozen."
Add Alpha and Beta to your IDE’s "unstable API usage" blacklist.
|
2.3.5. Internal packages
Any class in a package that is marked as internal (contains the word "internal") is not a part of the public API and may change in a backwards incompatible way. These classes and interfaces may be used across the Jdbi code base and can change (or be removed) without deprecation or announcement.
2.3.6. Mixing Jdbi component versions
There is no guarantee that Jdbi components of different versions (e.g. jdbi3-core version 1.2.3 and jdbi-sqlobject version 1.3.1) work together. Jdbi versioning is the public API exposed to consumers. All Jdbi components used in a project or service should use the same version. See the section on Build tools on how to use the BOM module to provide consistent versions for all components.
3. API Overview
Jdbi’s API comes in two flavors:
3.1. Fluent API
The Core API provides a fluent, imperative interface. Use Builder style objects to wire up your SQL to rich Java data types.
Jdbi jdbi = Jdbi.create("jdbc:h2:mem:test"); // (H2 in-memory database)
List<User> users = jdbi.withHandle(handle -> {
handle.execute("CREATE TABLE \"user\" (id INTEGER PRIMARY KEY, \"name\" VARCHAR)");
// Inline positional parameters
handle.execute("INSERT INTO \"user\" (id, \"name\") VALUES (?, ?)", 0, "Alice");
// Positional parameters
handle.createUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (?, ?)")
.bind(0, 1) // 0-based parameter indexes
.bind(1, "Bob")
.execute();
// Named parameters
handle.createUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (:id, :name)")
.bind("id", 2)
.bind("name", "Clarice")
.execute();
// Named parameters from bean properties
handle.createUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (:id, :name)")
.bindBean(new User(3, "David"))
.execute();
// Easy mapping to any type
return handle.createQuery("SELECT * FROM \"user\" ORDER BY \"name\"")
.mapToBean(User.class)
.list();
});
assertThat(users).containsExactly(
new User(0, "Alice"),
new User(1, "Bob"),
new User(2, "Clarice"),
new User(3, "David"));See the chapter introducing the core API for details about Jdbi’s fluent API.
3.2. Declarative API
The SQL Object extension is an additional module, which provides a declarative API.
Define the SQL to execute and the shape of the results by creating an annotated Java interface.
// Declare the API using annotations on a Java interface
public interface UserDao {
@SqlUpdate("CREATE TABLE \"user\" (id INTEGER PRIMARY KEY, \"name\" VARCHAR)")
void createTable();
@SqlUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (?, ?)")
void insertPositional(int id, String name);
@SqlUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (:id, :name)")
void insertNamed(@Bind("id") int id, @Bind("name") String name);
@SqlUpdate("INSERT INTO \"user\" (id, \"name\") VALUES (:id, :name)")
void insertBean(@BindBean User user);
@SqlQuery("SELECT * FROM \"user\" ORDER BY \"name\"")
@RegisterBeanMapper(User.class)
List<User> listUsers();
}Then attach the interface to a Jdbi instance and execute the methods on the resuling class to execute the SQL queries.
Jdbi jdbi = Jdbi.create("jdbc:h2:mem:test");
jdbi.installPlugin(new SqlObjectPlugin());
// Jdbi implements your interface based on annotations
List<User> userNames = jdbi.withExtension(UserDao.class, dao -> {
dao.createTable();
dao.insertPositional(0, "Alice");
dao.insertPositional(1, "Bob");
dao.insertNamed(2, "Clarice");
dao.insertBean(new User(3, "David"));
return dao.listUsers();
});
assertThat(userNames).containsExactly(
new User(0, "Alice"),
new User(1, "Bob"),
new User(2, "Clarice"),
new User(3, "David"));See the chapter on SQL objects for more details about the declarative API. The declarative API uses the fluent API "under the hood" and the two styles can be mixed.
4. Core API concepts
4.1. The Jdbi class
The Jdbi class is the main entry point into the library.
Each Jdbi instance maintains a set of configuration settings and wraps a JDBC DataSource.
Jdbi instances are thread-safe and do not own any database resources.
There are a few ways to create a Jdbi instance:
-
use a JDBC URL:
// H2 in-memory database
Jdbi jdbi = Jdbi.create("jdbc:h2:mem:test");-
directly use a
DataSourceobject which was created outside Jdbi.
DataSource ds = ...
Jdbi jdbi = Jdbi.create(ds);-
from a custom class that implements ConnectionFactory.
This allows for custom implementations of connection providers such as HA failover, proxy solutions etc.
-
from a single JDBC Connection.
Please note that there is no magic. Any Handle or operation will use this one connection provided. If the connection is thread-safe, then multiple threads accessing the database will work properly, if the connection object is not thread-safe, then Jdbi will not be able to do anything about it.
| Production code rarely provides a connection object directly to a Jdbi instance. It is useful for testing and debugging. |
Applications create a single, shared Jdbi instance per data source, and set up any common configuration there. See Configuration for more details.
Jdbi does not provide connection pooling or other High Availability features, but it can be combined with other software that does.
4.2. Handle
A Handle wraps an active database connection.
Handle instances are created by a Jdbi instance to provide a database connection e.g. for a single HTTP request or event callback). Handles are intended to be short-lived and must be closed to release the database connection and possible other resources.
A Handle is used to prepare and run SQL statements against the database, and manage database transactions. It provides access to fluent statement APIs that can bind arguments, execute the statement, and then map any results into Java objects.
A Handle inherits configuration from the Jdbi at the time it is created. See Configuration for more details.
Handles and all attached query objects such as Batch, Call, Query, Script and Update should be used by a single thread and are not thread-safe.
They may be used by multiple threads as long as there is coordination that only one thread at a time is accessing them. Managing Handles and query objects across threads is error-prone and should be avoided.
4.2.1. Obtaining a managed handle
The most convenient way to get access to a handle is by using the withHandle or useHandle methods on the Jdbi class. These methods use callbacks and provide a fully managed handle that is correctly closed and all related resources are released. withHandle allows the callback to return a result while useHandle is just executing operations that do not need to return any value.
Providing a return value from a query using the Jdbi#withHandle() method:
List<String> names = jdbi.withHandle(handle ->
handle.createQuery("select name from contacts")
.mapTo(String.class)
.list());
assertThat(names).contains("Alice", "Bob");Executing an operation using the Jdbi#useHandle() method:
jdbi.useHandle(handle -> {
handle.execute("create table contacts (id int primary key, name varchar(100))");
handle.execute("insert into contacts (id, name) values (?, ?)", 1, "Alice");
handle.execute("insert into contacts (id, name) values (?, ?)", 2, "Bob");
});
You may notice the "consumer" vs "callback" naming pattern in a few places in Jdbi. Callbacks return a value, and are coupled to with- methods. Consumers do not return a value, and are coupled to use- methods.
|
4.2.2. Managing the Handle lifecycle manually
The Jdbi#open() method returns an unmanaged handle.
The Java try-with-resources construct can be used to manage the lifecycle of the handle:
try (Handle handle = jdbi.open()) {
result = handle.execute("insert into contacts (id, name) values (?, ?)", 3, "Chuck");
}An unmanaged handle must be used when a stateful object should be passed to the calling code. Stateful objects are iterators and streams that do not collect data ahead of time in memory but provide a data stream from the database through the JDBC Connection to the calling code. Using a callback does not work here because the connection would be closed before the calling code can consume the data.
try (Handle handle = jdbi.open()) {
Iterator<String> names = handle.createQuery("select name from contacts where id = 1")
.mapTo(String.class)
.iterator();
assertThat(names).hasNext();
String name = names.next();
assertThat(name).isEqualTo("Alice");
assertThat(names).isExhausted();
}| When using Jdbi#open(), you should consider using try-with-resource or a try-finally block to ensure the handle is closed and the database connection is released. Failing to release the handle will leak connections. It is recommended to use a managed handle whenever possible. |
4.3. Statement types
Any database operation within Jdbi uses a statement. Multiple types of statements exist:
-
Query - SQL statements that return results, e.g. a
SELECTor any statement with aRETURNINGclause. See createQuery -
Update - SQL statements that return no value such as
INSERT,UPDATE,DELETEor a DDL operation. See createUpdate -
Batch - a set of operations that are executed as a batch. See createBatch
-
Call - execute a stored procedure. See createCall
-
Script - a SQL script containing multiple statements separated by
;that is executed as a batch. See createScript
4.3.1. Queries
A Query is a result-bearing SQL statement that returns a result set from the database.
List<Map<String, Object>> users =
handle.createQuery("SELECT id, \"name\" FROM \"user\" ORDER BY id ASC")
.mapToMap()
.list();
assertThat(users).containsExactly(
map("id", 1, "name", "Alice"),
map("id", 2, "name", "Bob"));There are many different methods to collect results from a query.
Use the ResultIterable#one() method returns when you expect the result to contain exactly one row. This method returns
null only if the returned row maps to null and throws an exception if the result has zero or multiple rows.
String name = handle.select("SELECT name FROM users WHERE id = ?", 3)
.mapTo(String.class)
.one();Use the ResultIterable#findOne() method when you expect the result to contain zero or one row. Returns
Optional.empty() if there are no rows, or one row that maps to null and throws an exception if the result has multiple rows.
Optional<String> name = handle.select(...)
.mapTo(String.class)
.findOne();Use the ResultIterable#first() method when you expect the result to contain at least one row. Returns
null if the first row maps to null. and throws an exception if the result has zero rows.
String name = handle.select("SELECT name FROM users WHERE id = ?", 3)
.mapTo(String.class)
.first();Use the ResultIterable#findFirst() method when the result may contain any number of rows. Returns
Optional.empty() if there are no rows, or the first row maps to null.
Optional<String> name = handle.select(...)
.mapTo(String.class)
.findFirst();Multiple result rows can be returned in a list or a set:
List<String> names = this.handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.list();
Set<String> names = handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.set();Use the ResultIterable#list() and Use the ResultIterable#set() methods use the default implementations from the collections framework.
For more control over the set and list types, use the ResultIterable#collectIntoList() and ResultIterable#collectIntoSet() methods which use the JdbiCollectors configuration object to retrieve the collection types for List and Set:
List<String> names = handle
.registerCollector(List.class, Collectors.toCollection(LinkedList::new))
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.collectIntoList();
Set<String> names = handle
.registerCollector(Set.class, Collectors.toCollection(LinkedHashSet::new))
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.collectIntoSet();The ResultIterable#collectInto() methods allows specifying a container type directly:
List<String> names = handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.collectInto(List.class); (1)
List<String> names = handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.collectInto(GenericTypes.parameterizeClass(List.class, String.class)); (2)| 1 | collect into a raw collection type |
| 2 | collect into a parameterized generic type |
For other collections, use ResultIterable#collect() with a collector or ResultIterable#toCollection() with a collection supplier:
Set<String> names = handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.collect(Collectors.toSet());
Set<String> names = handle
.createQuery("SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.toCollection(() -> new LinkedHashSet<>());The ResultIterable#collectToMap() method allows collecting results directly into a Map:
Map<Integer, String> names = handle
.registerRowMapper(Movie.class, ConstructorMapper.of(Movie.class))
.createQuery("SELECT * FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(Movie.class)
.collectToMap(Movie::id, Movie::title);You can also stream results:
List<String> names = new ArrayList<>();
handle.createQuery(
"SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.useStream(stream -> stream.forEach(names::add)); (1)
List<String> names = new ArrayList<>();
try (Stream<String> stream = handle.createQuery(
"SELECT title FROM films WHERE genre = :genre ORDER BY title")
.bind("genre", "Action")
.mapTo(String.class)
.stream()) { (2)
stream.forEach(names::add);
}| 1 | ResultIterable#useStream() and ResultIterable#withStream() provide a callback with a managed stream object. |
| 2 | ResultIterable#stream() provides a stream that must be managed by user code |
Equivalent methods for iterators exist as well.
Thus far, all examples have shown a String result type. Of course, you can
map to many other data types such as an integer:
int releaseDate = handle
.createQuery("SELECT release_year FROM films WHERE title = :title")
.bind("title", "The Dark Knight")
.mapTo(Integer.class)
.one();Or a complex, custom type:
Movie movie = handle
.registerRowMapper(Movie.class, ConstructorMapper.of(Movie.class))
.createQuery("SELECT * FROM films WHERE id = :id")
.bind("id", 1)
.mapTo(Movie.class)
.one();4.3.2. Updates
Updates are operations that return an integer number of rows modified, such as a database INSERT, UPDATE, or DELETE.
You can execute a simple update with Handle's int execute(String sql, Object… args)
method which binds simple positional parameters.
count = handle.execute("INSERT INTO \"user\" (id, \"name\") VALUES(?, ?)", 4, "Alice");
assertThat(count).isOne();To further customize, use createUpdate:
int count = handle.createUpdate("INSERT INTO \"user\" (id, \"name\") VALUES(:id, :name)")
.bind("id", 3)
.bind("name", "Charlie")
.execute();
assertThat(count).isOne();Updates may return Generated Keys instead of a result count.
4.3.3. Batches
A Batch sends many commands to the server in bulk.
After opening the batch, repeated add statements, and invoke add.
Batch batch = handle.createBatch();
batch.add("INSERT INTO fruit VALUES(0, 'apple')");
batch.add("INSERT INTO fruit VALUES(1, 'banana')");
int[] rowsModified = batch.execute();The statements are sent to the database in bulk, but each statement is executed separately.
There are no parameters. Each statement returns a modification count, as with an Update, and
those counts are then returned in an int[] array. In common cases all elements will be 1.
Some database drivers might return special values in conditions where modification counts are not available. See the executeBatch documentation for details.
4.3.4. Prepared Batches
A PreparedBatch sends one statement to the server with many argument sets. The statement is executed repeatedly, once for each batch of arguments that is add-ed to it.
The result is again a int[] of modified row count.
PreparedBatch batch = handle.prepareBatch("INSERT INTO \"user\" (id, \"name\") VALUES(:id, :name)");
for (int i = 100; i < 5000; i++) {
batch.bind("id", i).bind("name", "User:" + i).add();
}
int[] counts = batch.execute();SqlObject also supports batch inserts:
public void testSqlObjectBatch() {
BasketOfFruit basket = handle.attach(BasketOfFruit.class);
int[] rowsModified = basket.fillBasket(Arrays.asList(
new Fruit(0, "apple"),
new Fruit(1, "banana")));
assertThat(rowsModified).containsExactly(1, 1);
assertThat(basket.countFruit()).isEqualTo(2);
}
public interface BasketOfFruit {
@SqlBatch("INSERT INTO fruit VALUES(:id, :name)")
int[] fillBasket(@BindBean Collection<Fruit> fruits);
@SqlQuery("SELECT count(1) FROM fruit")
int countFruit();
}| Batching dramatically increases efficiency over repeated single statement execution, but many databases don’t handle extremely large batches well either. Test with your database configuration, but often extremely large data sets should be divided and committed in pieces - or risk bringing your database to its knees. |
Exception Rewriting
The JDBC SQLException class is very old and predates more modern exception facilities like Throwable’s suppressed exceptions. When a batch fails, there may be multiple failures to report, which could not be represented by the base Exception types of the day.
So SQLException has a bespoke getNextException chain to represent the causes of a batch failure. Unfortunately, by default most logging libraries do not print these exceptions out, pushing their handling into your code. It is very common to forget to handle this situation and end up with logs that say nothing other than
java.sql.BatchUpdateException: Batch entry 1 INSERT INTO something (id, name) VALUES (0, '') was aborted. Call getNextException to see the cause.Jdbi will rewrite such exceptions into "suppressed exceptions" so that your logs are more helpful:
java.sql.BatchUpdateException: Batch entry 1 INSERT INTO something (id, name) VALUES (0, 'Keith') was aborted. Call getNextException to see the cause.
Suppressed: org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "something_pkey"
Detail: Key (id)=(0) already exists.4.3.5. Stored Procedure Calls
A Call invokes a database stored procedure.
Let’s assume an existing stored procedure as an example:
CREATE FUNCTION add(a IN INT, b IN INT, sum OUT INT) AS $$
BEGIN
sum := a + b;
END;
$$ LANGUAGE plpgsqlHere’s how to call a stored procedure:
OutParameters result = handle
.createCall("{:sum = call add(:a, :b)}") (1)
.bind("a", 13) (2)
.bind("b", 9) (2)
.registerOutParameter("sum", Types.INTEGER) (3) (4)
.invoke(); (5)| 1 | Call Handle.createCall() with the SQL statement. Note that JDBC has a
peculiar SQL format when calling stored procedures, which we must follow. |
| 2 | Bind input parameters to the procedure call. |
| 3 | Register out parameters, the values that will be returned from the stored procedure call. This tells JDBC what data type to expect for each out parameter. |
| 4 | Out parameters may be registered by name (as shown in the example) or by zero-based index, if the SQL is using positional parameters. Multiple output parameters may be registered, depending on the output of the stored procedure itself. |
| 5 | Finally, call invoke() to execute the procedure. |
Invoking the stored procedure returns an OutParameters object, which contains the value(s) returned from the stored procedure call.
Now we can extract the result(s) from OutParameters:
int sum = result.getInt("sum");It is possible to return open cursors as a result-like object by declaring it
as Types.REF_CURSOR and then inspecting it via OutParameters.getRowSet().
Usually this must be done in a transaction, and the results must be consumed
before closing the statement by processing it using the Call.invoke(Consumer)
or Call.invoke(Function) callback style.
| Due to design constraints within JDBC, the parameter data types available through OutParameters is limited to those types supported directly by JDBC. This cannot be expanded through e.g. mapper registration. |
4.3.6. Scripts
A Script parses a String into semicolon terminated statements. The statements can be executed in a single Batch or individually.
try (Script script = handle.createScript("INSERT INTO \"user\" VALUES(3, 'Charlie');"
+ "UPDATE \"user\" SET \"name\"='Bobby Tables' WHERE id=2;")) {
int[] results = script.execute();
assertThat(results).containsExactly(1, 1);
}4.3.7. Metadata
Jdbi allows access to the Database Metadata through queryMetadata methods on the Handle.
Simple values can be queried directly using a method reference:
String url = h.queryMetadata(DatabaseMetaData::getURL);
boolean supportsTransactions = h.queryMetadata(DatabaseMetaData::supportsTransactions);Many methods on the DatabaseMetaData return a ResultSet. These can be used with the queryMetadata method that returns a ResultBearing.
All Jdbi Row Mappers and Column Mappers are available to map these results:
List<String> catalogNames = h.queryMetadata(DatabaseMetaData::getCatalogs)
.mapTo(String.class)
.list();4.4. Usage in asynchronous applications
Calling Jdbc and by extension Jdbi is inherently a blocking operation. In asynchronous applications (where results are returned as a CompletionStage or a CompletableFuture) it is very important never to block on threads that the caller doesn’t control. For this, there is the JdbiExcecutor class that wraps around a Jdbi instance and makes sure calls are made on a specific thread pool.
To create a JdbiExcecutor instance, we first need to create a Jdbi instance (see The Jdbi class). Then pass that instance into JdbiExecutor.create():
Executor executor = Executors.newFixedThreadPool(8);
JdbiExecutor jdbiExecutor = JdbiExecutor.create(h2Extension.getJdbi(), executor);It is important to size the executor to the specific implementation. See here for some hints.
To use the jdbiExecutor, we make similar calls to JdbiExcecutor
as we do to Jdbi
CompletionStage<Void> futureResult = jdbiExecutor.useHandle(handle -> {
handle.execute("insert into contacts (id, name) values (?, ?)", 3, "Erin");
});
// wait for stage to complete (don't do this in production code!)
futureResult.toCompletableFuture().join();
assertThat(h2Extension.getSharedHandle().createQuery("select name from contacts where id = 3")
.mapTo(String.class)
.list()).contains("Erin");Or
CompletionStage<List<String>> futureResult = jdbiExecutor.withHandle(handle -> {
return handle.createQuery("select name from contacts where id = 1")
.mapTo(String.class)
.list();
});
assertThat(futureResult)
.succeedsWithin(Duration.ofSeconds(10))
.asList()
.contains("Alice");Or
CompletionStage<String> futureResult =
jdbiExecutor.withExtension(SomethingDao.class, dao -> dao.getName(1));
assertThat(futureResult)
.succeedsWithin(Duration.ofSeconds(10))
.isEqualTo("Alice");Note, since the handle closes as soon as the callback returns, you cannot return an iterator, since iteration will call upon the (now closed) handle
CompletionStage<Iterator<String>> futureResult = jdbiExecutor.withHandle(handle -> {
return handle.createQuery("select name from contacts where id = 1")
.mapTo(String.class)
.iterator();
});
// wait for stage to complete (don't do this in production code!)
Iterator<String> result = futureResult.toCompletableFuture().join();
// result.hasNext() fails because the handle is already closed at this point
assertThatException().isThrownBy(() -> result.hasNext());5. Resource Management
JDBC operations involve stateful objects: Connection, PreparedStatement and ResultSet are the most common ones. Jdbi understands the lifecycle of these objects and can often fully manage them.
Within Jdbi, two types of stateful objects exist that need to be managed: Handle objects and all Statement objects.
Manual resource management for Jdbi objects uses the standard Java try-with-resources construct:
try (Handle handle = jdbi.open();
Query query = handle.createQuery("SELECT * from users")) {
List<User> users = query.mapTo(User.class).list();
}5.1. Automatic resource management
Jdbi can manage and release resources automatically, so that try-with-resources blocks are often not needed.
Automatic resource management is only available with the SQL Object API and the Extension API. In these situations, Jdbi can manage all resources:
-
with methods on a SQL object that was created with Jdbi#onDemand():
UserDao userDao = jdbi.onDemand(UserDao.class);
User user = userDao.getUser(id);
public interface UserDao {
@SqlQuery("SELECT * FROM users WHERE id = :id")
@UseRowMapper(UserMapper.class)
User getUser(@Bind("id") int id);
}-
with the Jdbi withExtension and useExtension callbacks:
User user = jdbi.withExtension(UserDao.class, dao -> dao.getUser(id));
public interface UserDao {
@SqlQuery("SELECT * FROM users WHERE id = :id")
@UseRowMapper(UserMapper.class)
User getUser(@Bind("id") int id);
}5.2. Handle resource management
Any time a handle is explicitly opened, it must be managed by the calling code. A try-with-resources block is the best way to do this:
try (Handle handle = jdbi.open()) {
// handle operations here
}Closing the handle releases the connection that is managed by the handle. Handle resource management is only necessary when using the various Jdbi#open() methods on the Jdbi object. Any handle that is passed in through a callback (Jdbi#withHandle(), Jdbi#useHandle(), Jdbi#inTransaction(), Jdbi#useTransaction()) is managed through Jdbi:
Jdbi is still able to manage statement resources even if the handle is managed manually:
try (Handle handle = jdbi.open()) { (1)
UserDao dao = handle.attach(UserDao.class);
User user = userDao.getUser(id);
}
User user = jdbi.withHandle(handle -> { (2)
UserDao dao = handle.attach(UserDao.class);
return userDao.getUser(id);
});
public interface UserDao {
@SqlQuery("SELECT * FROM users WHERE id = :id")
@UseRowMapper(UserMapper.class)
User getUser(@Bind("id") int id);
}| 1 | Jdbi.open() creates a new Handle that must be managed through a try-with-resources block. |
| 2 | jdbi.withHandle() passes a managed Handle to the callback and does not require management. |
5.3. Statement resource management
All statement types may use resources that need to be released. There are multiple ways to do; each has its advantages and drawbacks:
-
Explicit statement resource management uses code to manage and release resources
-
Implicit statement resource cleanup relies on the Jdbi framework to release the resources when necessary
-
Attaching statements to the handle lifecycle delegates to the Handle lifecycle
5.3.1. Explicit statement resource management
All SQL statement types implement the AutoCloseable interface and can be used in a try-with-resources block. This is the recommended way to manually manage statements, and it ensures that all resources are properly released when they are no longer needed. The try-with-resources pattern ensures that the close() method on the SQL statement is called which releases the resources.
Create, execute and release 100,000 update statements:
try (Handle handle = jdbi.open()) {
for (int i = 0; i < 100_000; i++) {
try (Update update = handle.createUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")) {
update.bind("id", i)
.bind("name", "user_" + i)
.execute();
}
}
}It is not necessary to use a try-with-resources block, the close() method can be called manually as well:
try (Handle handle = jdbi.open()) {
for (int i = 0; i < 100_000; i++) {
Update update = handle.createUpdate("INSERT INTO users (id, name) VALUES (:id, :name)");
try {
update.bind("id", i)
.bind("name", "user_" + i)
.execute();
} finally {
update.close();
}
}
}Explicit statement resource management, while a bit more involved ensures that all resources are always correctly released, especially when there are exceptions thrown during statement execution. While many examples and demo code omit managing the statement types, it is strongly recommended to do so.
5.3.2. Implicit statement resource cleanup
If possible, Jdbi will help with resource management through implicit resource cleanup.
If a SQL statement operation succeeds and all data returned by the database was consumed, then Jdbi will release the allocated resources even if the statement is used without a try-with-resources block.
All terminal operations on the ResultIterable interface, except for the stream() and iterator() methods, consume all data from the database, even if they return only a subset (e.g. findOne()). The same applies for operations such as Update or Batch.
For all other operations, the resources will be released if the operation succeeds and does not throw an exception.
try (Handle handle = jdbi.open()) {
List<User> users = handle
.createQuery("SELECT * from users") (1)
.mapTo(User.class) (2)
.list(); (3)
}| 1 | creates a Query object |
| 2 | returns an object implementing ResultIterable |
| 3 | is a terminal operation that consumes all the data from the database |
As long as no exception is thrown, this example above will release all resources allocated by the Query object, even though it is not managed.
| This code that works well as long as nothing goes awry! If an unmanaged SQL statement operation fails halfway through (e.g. with a connection timeout or a database problem), then resources will not be cleanup up by Jdbi. This may lead to resource leaks that are difficult to find or reproduce. Some JDBC drivers will also clean up resources that they hand out (such as JDBC statements or ResultSet objects) when a connection is closed. In these situations, resources may be released eventually when the handle is closed (which also closes the JDBC connection). This is highly driver dependent and should not be relied upon. |
5.3.3. Resources with Streams and Iterators
Most methods on objects that implement ResultIterable are terminal. They consume all data returned by the database and will release statement resources at the end. All of these methods may buffer results in memory, something that is not acceptable for very large data sets or when data needs to be streamed.
| Just using an iterator or stream may not be enough to actually stream data without buffering it in memory. Often the JDBC driver might still buffer data. See the documentation for your database on how to ensure that the driver does not buffer all the results in memory. |
For these use cases, Jdbi offers the stream() and iterator() methods, which return lazy-loading objects that return data from the database row by row. These objects are stateful and must be managed.
The stream and iterator objects provided by Jdbi will release all their resources when the data stream from the database is exhausted or when an instance is explicitly closed. Standard Java Streams support the try-with-resources pattern directly; the iterator() method returns a ResultIterator object which extends AutoCloseable.
When using a stream or iterator, either the statement or the result object must be managed. Calling close() on either the statement or the stream/iterator will terminate the operation and release all resources.
// managing resources through the query SQL statement
try (Handle handle = jdbi.open()) {
try (Query query = handle.createQuery("SELECT * from users")) { (1)
Stream<User> users = query.mapTo(User.class).stream();
// consume the stream
}
}
// managing resources through the stream
try (Handle handle = jdbi.open()) {
try (Stream<User> users = handle.createQuery("SELECT * from users")
.mapTo(User.class)
.stream()) { (2)
// consume the stream
}
}| 1 | use a try-with-resources block with the Query object releases the resources and closes the stream when the block is left |
| 2 | use a try-with-resources block with the stream releases the resources and closes the stream when the block is left |
The same pattern applies to a result iterator.
Streams and iterators are cursor-type "live" objects. They require an active statement and result set. Any operation that closes and releases these resources will cause future operations on the stream or iterator to fail.
The following code does not work:
Stream<User> userStream = jdbi.withHandle(handle ->
handle.createQuery("SELECT * from users")
.mapTo(User.class)
.stream(); (1)
}); (2)
Optional<User> user = stream.findFirst(); (3)| 1 | Creates a stream object backed by the open result set of the query |
| 2 | leaving the callback closes the handle and releases all resources including the result set |
| 3 | throws an exception because the result set has already been closed |
This can be avoided by using one of the callback methods that ResultIterable offers: withIterator(), useIterator(), withStream(), useStream(). Each of these methods manages the iterator / stream through Jdbi and allow consumption of its contents within a callback:
try (Handle handle = jdbi.open()) {
try (Query query = handle.createQuery("SELECT * from users")) {
query.mapTo(User.class).useIterator(it -> {
// consume the iterator contents
});
}
}While it is not strictly necessary to execute the query in a try-with-resources block because the useIterator() method will close the iterator and release all resources from the query, it is good practice and guards against possible errors that may happen between the creation of the query and the callback execution.
Using a jdbi callback allows fully automated resource management:
jdbi.useHandle(handle -> {
handle.createQuery("SELECT * from users")
.mapTo(User.class)
.useIterator(it -> {
// consume the iterator contents
});
});5.3.4. Attaching statements to the handle lifecycle
An elegant way to manage resources is attaching the statement to the handle lifecycle. Calling the attachToHandleForCleanup() method, which is available on SQL statements, associates the statement with the handle. When the handle is closed, all attached statements that have not been cleaned up yet, will also be released.
Optional<User> user = handle.createQuery("SELECT * FROM users WHERE id = :id")
.attachToHandleForCleanup() (1)
.bind("id", id)
.mapTo(User.class)
.stream()
.findAny();| 1 | By attaching the statement to the handle, all resources are now managed by Jdbi and released even if the operation throws an exception. |
This works best for short-lived handles with a few statement operations. As the resources may not be released until the handle is closed, executing a large number of SQL statements that all may need cleaning up could lead to resource exhaustion. When in doubt, prefer the try-with-resources construct over attaching a SQL statements to the handle.
It is possible to attach all created statements by default to a handle by calling setAttachAllStatementsForCleanup(true) on the SqlStatements config object:
jdbi.getConfig(SqlStatements.class)
.setAttachAllStatementsForCleanup(true);
try (Handle handle = jdbi.open()) {
Optional<User> user = handle.createQuery("SELECT * FROM users WHERE id = :id")
.bind("id", id)
.mapTo(User.class)
.stream()
.findAny();
}This setting can be controlled either per Jdbi object or per Handle.
try (Handle handle = jdbi.open()) {
handle.getConfig(SqlStatements.class)
.setAttachAllStatementsForCleanup(true);
Optional<User> user = handle.createQuery("SELECT * FROM users WHERE id = :id")
.bind("id", id)
.mapTo(User.class)
.stream()
.findAny();
}As a special case, any method on the Jdbi object that takes a callback (withHandle, useHandle, inTransaction, useTransaction) attaches statements created in the callback by default to the handle passed into the callback. These handles are fully managed and will be closed when the callback exits.
User user = jdbi.withHandle(handle ->
handle.createQuery("SELECT * FROM users WHERE id = :id")
.bind("id", id)
.mapTo(User.class)
.one());This behavior can be controlled through the setAttachCallbackStatementsForCleanup() method. If a callback executes a huge number of statements, it may be preferable to manage resources manually:
jdbi.useHandle(handle -> {
handle.getConfig(SqlStatements.class).setAttachCallbackStatementsForCleanup(false); (1)
for (int i = 0; i < 100_000; i++) {
try (Update update = handle.createUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")) {
update.bind("id", i)
.bind("name", "user_" + i)
.execute();
}
}
});| 1 | Turn off automatic attachment of statements to the handle because the callback creates a large number of statements. Modifying this value only changes the setting for the current handle; it does not affect the global setting associated with the Jdbi object that created the handle. |
While the attachAllStatementsForCleanup setting affects all statements created outside a Jdbi callback (withHandle, useHandle, inTransaction, useTransaction), inside these callbacks, the behavior is controlled by the attachCallbackStatementsForCleanup setting.
The default value for the attachAllStatementsForCleanup is false while the default value for attachCallbackStatementsForCleanup is true.
|
6. Arguments
Arguments are Jdbi’s representation of JDBC statement parameters (the ? in SELECT * FROM Foo WHERE bar = ?).
To set a parameter ? on a JDBC PreparedStatement, you would ps.setString(1, "Baz").
With Jdbi, when you bind the string "Baz", it will search through all registered ArgumentFactory instances
until it finds one that is willing to convert the String into an Argument.
The argument is responsible for setting the String for the placeholder exactly as setString does.
Arguments can perform more advanced bindings than simple JDBC supports: a BigDecimal could be bound as a SQL decimal, a java.time.Year as a SQL int, or a complex object could be serialized to a byte array and bound as a SQL blob.
The use of Jdbi arguments is limited to JDBC prepared statement parameters.
Notably, arguments usually cannot be used to change the structure of a query
(for example the table or column name, SELECT or INSERT, etc.)
nor may they be interpolated into string literals.
See Query Templating and TemplateEngine for more information.
|
6.1. Positional Arguments
When a SQL statement uses ? tokens, Jdbi can bind a values to parameters
at the corresponding index (0-based):
handle.createUpdate("insert into contacts (id, name) values (?, ?)")
.bind(0, 3)
.bind(1, "Chuck")
.execute();
String name = handle.createQuery("select name from contacts where id = ?")
.bind(0, 3)
.mapTo(String.class)
.one();6.2. Named Arguments
When a SQL statement uses colon-prefixed tokens like :name, Jdbi can bind
parameters by name:
handle.createUpdate("insert into contacts (id, name) values (:id, :name)")
.bind("id", 3)
.bind("name", "Chuck")
.execute();
String name = handle.createQuery("select name from contacts where id = :id")
.bind("id", 3)
.mapTo(String.class)
.one();Names can contain alphanumeric characters, dot and dash (. and -).
By default, Jbdi uses the see the ColonPrefixSqlParser that understands
the :foo syntax. This can be changed if the colon is problematic in the SQL dialect used. Jdbi includes support for an alternate #foo syntax out-of-the-box using the HashPrefixSqlParser. It is also possible to create custom parsers for named arguments.
|
| Mixing named and positional arguments is not allowed, as it would become confusing very quickly. |
6.3. Supported Argument Types
Out of the box, Jdbi supports the following types as SQL statement arguments:
-
Primitives:
boolean,byte,short,int,long,char,float, anddouble -
java.lang:
Boolean,Byte,Short,Integer,Long,Character,Float,Double,String, andEnum(stored as the enum value’s name by default) -
java.math:
BigDecimal -
java.net:
Inet4Address,Inet6Address,URL, andURI -
java.sql:
Blob,Clob,Date,Time, andTimestamp -
java.time:
Instant,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,ZonedDateTime, andZoneId -
java.util:
Date, Optional (around any other supported type), andUUID -
java.util.Collectionand Java arrays (stored as SQL arrays). Some additional setup may be required depending on the type of array element.
You can also configure Jdbi to support additional argument types. More on that later.
6.4. Binding Arguments
Arguments to SQL statement can be bound in a few different ways.
You can bind individual arguments:
handle.createUpdate("INSERT INTO contacts (id, name) VALUES (:id, :name)")
.bind("id", 1)
.bind("name", "Alice")
.execute();You can bind multiple arguments at once from the entries of a Map:
Map<String, Object> contact = new HashMap<>();
contact.put("id", 2)
contact.put("name", "Bob");
handle.createUpdate("INSERT INTO contacts (id, name) VALUES (:id, :name)")
.bindMap(contact)
.execute();You can bind multiple values at once, from either a List<T> or a vararg:
List<String> keys = new ArrayList<String>()
keys.add("user_name");
keys.add("street");
handle.createQuery("SELECT value FROM items WHERE kind in (<listOfKinds>)")
.bindList("listOfKinds", keys)
.mapTo(String.class)
.list();
// or, using the 'vararg' definition
handle.createQuery("SELECT value FROM items WHERE kind in (<varargListOfKinds>)")
.bindList("varargListOfKinds", "user_name", "docs", "street", "library")
.mapTo(String.class)
.list();
Using bindList requires writing your SQL with an attribute, not a binding,
despite the fact that your values are bound. The attribute is a placeholder that will be
safely rendered to a comma-separated list of binding placeholders.
|
You can bind multiple arguments from properties of a Java Bean:
Contact contact = new Contact();
contact.setId(3);
contact.setName("Cindy");
handle.createUpdate("INSERT INTO contacts (id, name) VALUES (:id, :name)")
.bindBean(contact)
.execute();You can also bind an Object’s public fields:
Object contact = new Object() {
public int id = 0;
public String name = "Cindy";
};
handle.createUpdate("INSERT INTO contacts (id, name) VALUES (:id, :name)")
.bindFields(contact)
.execute();Alternatively, you can bind public, parameter-less methods of an Object:
Object contact = new Object() {
public int theId() {
return 0;
}
public String theName() {
return "Cindy";
}
};
handle.createUpdate("INSERT INTO contacts (id, name) VALUES (:theId, :theName)")
.bindMethods(contact)
.execute();Optionally, you can qualify each bound bean/object with a prefix. This can help remove ambiguity in situations where two or more bound beans have similar property names:
Folder folder = new Folder(1, "Important Documents");
Document document =
new Document(100, "memo.txt", "Business business business. Numbers.");
handle.createUpdate("INSERT INTO documents (id, folder_id, name, contents) " +
"VALUES (:d.id, :f.id, :d.name, :d.contents)")
.bindBean("f", folder)
.bindMethods("f", folder)
.bindFields("d", document)
.execute();
bindBean(), bindFields(), and bindMethods() may be used to bind nested
properties, e.g. :user.address.street.
|
bindMap() does not bind nested properties—map keys are expected to exactly
match the bound parameter name.
|
| The authors recommend checking out Immutables support for an advanced way to easily bind and map value types. |
6.5. Argument Annotations
-
@JdbiProperty(bind=false)allows configuring whether a discovered property is bound as an argument. Turn thebindannotation value off, and the property discovery mechanism will ignore it.
6.6. Custom Arguments
Occasionally your data model will use data types not natively supported by Jdbi (see Supported Argument Types).
Fortunately, Jdbi can be configured to bind custom data types as arguments, by implementing a few simple interfaces.
| Core JDBC features are generally well-supported by all database vendors. However, more advanced usages like array support or geometry types tend to quickly become vendor-specific. |
6.6.1. Using the Argument interface
The Argument interface wraps a single value into a binding.
static class UUIDArgument implements Argument {
private UUID uuid;
UUIDArgument(UUID uuid) {
this.uuid = uuid;
}
@Override
public void apply(int position, PreparedStatement statement, StatementContext ctx) throws SQLException {
statement.setString(position, uuid.toString()); (1)
}
}
@Test
public void uuidArgument() {
UUID u = UUID.randomUUID();
assertThat(handle.createQuery("SELECT CAST(:uuid AS VARCHAR)")
.bind("uuid", new UUIDArgument(u))
.mapTo(String.class)
.one()).isEqualTo(u.toString());
}| 1 | Since Argument usually directly calls into JDBC directly, it is given the one-based index (as expected by JDBC) when it is applied. |
Here we use an Argument to directly bind a UUID. In this particular case, the most obvious approach is to send the UUID to the database as a String. If your JDBC driver supports custom types directly or efficient binary transfers, you can leverage them easily here.
6.6.2. Using the ArgumentFactory interface
The ArgumentFactory interface provides Argument interface instances for any data type it knows about. By implementing and registering an argument factory, it is possible to bind custom data types without having to explicitly wrap them in objects implementing the Argument interface.
Jdbi provides an AbstractArgumentFactory class which simplifies implementing the ArgumentFactory contract:
static class UUIDArgumentFactory extends AbstractArgumentFactory<UUID> {
UUIDArgumentFactory() {
super(Types.VARCHAR); (1)
}
@Override
protected Argument build(UUID value, ConfigRegistry config) {
return (position, statement, ctx) -> statement.setString(position, value.toString()); (2)
}
}
@Test
public void uuidArgumentFactory() {
UUID u = UUID.randomUUID();
handle.registerArgument(new UUIDArgumentFactory());
assertThat(handle.createQuery("SELECT CAST(:uuid AS VARCHAR)")
.bind("uuid", u)
.mapTo(String.class)
.one()).isEqualTo(u.toString());
}| 1 | The JDBC SQL type constant to use when
binding UUIDs. Jdbi needs this in order to bind UUID values of null. See
PreparedStatement.setNull(int,int) |
| 2 | Since Argument is a functional interface, it can be implemented as a lambda expression. |
6.6.3. Using Prepared Arguments for batches
Traditional argument factories decide to bind based on both the type and actual value of the binding.
This is very flexible but when binding a large PreparedBatch it incurs a serious performance penalty
as the entire chain of argument factories must be consulted for each batch of arguments added.
To address this issue, implement ArgumentFactory.Preparable which promises to handle all values
of a given Type. Most built in argument factories now implement the Preparable interface.
Preparable argument factories are consulted before traditional argument factories. If you’d prefer
to keep the old behavior, you may disable this feature with getConfig(Arguments.class).setPreparedArgumentsEnabled(false).
6.6.4. The Arguments Registry
When you register an ArgumentFactory, the registration is stored in an
Arguments instance held by Jdbi.
Arguments is a configuration class, which stores all registered argument
factories (including the factories for built-in arguments).
Under the hood, when you bind arguments to a statement, Jdbi consults the
Arguments config object and searches for an ArgumentFactory which knows how
to convert a bound object into an Argument.
Later, when the statement is executed, each Argument located during binding
is applied to the JDBC
PreparedStatement.
| Occasionally, two or more argument factories will support arguments of the same data type. When this happens, the last-registered factory wins. Preparable argument factories always take precedence over base argument factories. This means that you can override the way any data type is bound, including the data types supported out of the box. |
7. Mappers
Jdbi makes use of mappers to convert result data into Java objects. There are two types of mappers:
-
Row Mappers, which map a full row of result set data.
-
Column Mappers, which map a single column of a result set row.
7.1. Row Mappers
RowMapper is a functional interface, which maps the current row of a JDBC ResultSet to a mapped type. Row mappers are invoked once for each row in the result set.
Since RowMapper is a functional interface, they can be provided inline to a query using a lambda expression:
List<User> users = handle.createQuery("SELECT id, \"name\" FROM \"user\" ORDER BY id ASC")
.map((rs, ctx) -> new User(rs.getInt("id"), rs.getString("name")))
.list();
There are three different types being used in the above example. Query,
returned by Handle.createQuery(), implements the ResultBearing interface.
The ResultBearing.map() method takes a RowMapper<T> and returns a
ResultIterable<T>. Finally, ResultBearing.list() collects each row in the
result set into a List<T>.
|
Row mappers may be defined as classes, which allows for re-use:
class UserMapper implements RowMapper<User> {
@Override
public User map(ResultSet rs, StatementContext ctx) throws SQLException {
return new User(rs.getInt("id"), rs.getString("name"));
}
}List<User> users = handle.createQuery("SELECT id, \"name\" FROM \"user\" ORDER BY id ASC")
.map(new UserMapper())
.list();This RowMapper is equivalent to the lambda mapper above but more explicit.
7.1.1. RowMappers registry
Row mappers can be registered for particular types. This simplifies usage, requiring only that you specify what type you want to map to. Jdbi automatically looks up the mapper from the registry, and uses it.
jdbi.registerRowMapper(User.class,
(rs, ctx) -> new User(rs.getInt("id"), rs.getString("name"));
try (Handle handle = jdbi.open()) {
List<User> users = handle
.createQuery("SELECT id, name FROM user ORDER BY id ASC")
.mapTo(User.class)
.list();
}A mapper which implements RowMapper with an explicit mapped type (such as the
UserMapper class in the previous section) may be registered without specifying
the mapped type:
handle.registerRowMapper(new UserMapper());When this method is used, Jdbi inspects the generic class signature of the mapper to automatically discover the mapped type.
It is possible to register more than one mapper for any given type. When this happens, the last-registered mapper for a given type takes precedence. This permits optimizations, like registering a "default" mapper for some type, while allowing that default mapper to be overridden with a different one when appropriate.
7.1.2. RowMapperFactory
A RowMapperFactory can produce row mappers for arbitrary types.
Implementing a factory might be preferable to a regular row mapper if:
-
The mapper implementation is generic, and could apply to multiple mapped types. For example, Jdbi provides a generalized BeanMapper, which maps columns to bean properties for any bean class.
-
The mapped type has a generic signature, and/or the mapper could be composed of other registered mappers. For example, Jdbi provides a Map.Entry<K,V> mapper, provided a mapper is registered for types
KandV. -
You want to bundle multiple mappers into a single class.
Let’s take an example Pair<L, R> class:
public final class Pair<L, R> {
public final L left;
public final R right;
public Pair(L left, R right) {
this.left = left;
this.right = right;
}
}Now, let’s implement a row mapper factory. The factory should produce a
RowMapper<Pair<L, R>> for any Pair<L, R> type, where the L type is mapped
from the first column, and R from the second—assuming there are column
mappers registered for both L and R.
Let’s take this one step at a time:
public class PairMapperFactory implements RowMapperFactory {
public Optional<RowMapper<?>> build(Type type, ConfigRegistry config) {
// ...
}
}The build method accepts a mapped type, and a config registry. It may return
Optional.of(someMapper) if it knows how to map that type, or
Optional.empty() otherwise.
First we check whether the mapped type is a Pair:
if (!Pair.class.equals(GenericTypes.getErasedType(type))) {
return Optional.empty();
}
The GenericTypes utility class is discussed in Working with Generic Types.
|
Next, we extract the L and R generic parameters from the mapped type:
Type leftType = GenericTypes.resolveType(Pair.class.getTypeParameters()[0], type);
Type rightType = GenericTypes.resolveType(Pair.class.getTypeParameters()[1], type);In the first line, Pair.class.getTypeParameters()[0] gives the type variable
L. Likewise in the second line, Pair.class.getTypeParameters()[1] gives the type
variable R.
We use resolveType() to resolve the types for the L and R type variables
in the context of the mapped type.
Now that we have the types for L and R, we can look up the column mappers
for those types from the ColumnMappers config class, through the config
registry:
ColumnMappers columnMappers = config.get(ColumnMappers.class);
ColumnMapper<?> leftMapper = columnMappers.findFor(leftType)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for Pair left parameter " + leftType));
ColumnMapper<?> rightMapper = columnMappers.findFor(rightType)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for Pair right parameter " + rightType));The config registry is a locator for config classes. So when we call
config.get(ColumnMappers.class), we get back a ColumnMappers instance with
the current column mapper configuration.
Next we call ColumnMappers.findFor() to get the column mappers for the left
and right types.
You may have noticed that although this method can return Optional, we are
throwing an exception if we can’t find the left- or right-hand mappers. We have
found this to be a best practice: return Optional.empty() if the factory
knows nothing about the mapped type (Pair, in this case). If it knows the
mapped type but is missing some configuration to make it work (e.g. mappers not
registered for L or R parameter) it is more helpful to throw an exception
with an informative message, so users can diagnose why the mapper is not
working as expected.
|
Finally, we construct a pair mapper, and return it:
RowMapper<?> pairMapper = (rs, ctx) ->
new Pair(leftMapper.map(rs, 1, ctx), // In JDBC, column numbers start at 1
rightMapper.map(rs, 2, ctx));
return Optional.of(pairMapper);Here is the factory class all together:
public class PairMapperFactory implements RowMapperFactory {
public Optional<RowMapper<?>> build(Type type, ConfigRegistry config) {
if (!Pair.class.equals(GenericTypes.getErasedType(type))) {
return Optional.empty();
}
Type leftType = GenericTypes.resolveType(Pair.class.getTypeParameters()[0], type);
Type rightType = GenericTypes.resolveType(Pair.class.getTypeParameters()[1], type);
ColumnMappers columnMappers = config.get(ColumnMappers.class);
ColumnMapper<?> leftMapper = columnMappers.findFor(leftType)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for Pair left parameter " + leftType));
ColumnMapper<?> rightMapper = columnMappers.findFor(rightType)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for Pair right parameter " + rightType));
RowMapper<?> pairMapper = (rs, ctx) -> new Pair(leftMapper.map(rs, 1, ctx),
rightMapper.map(rs, 2, ctx));
return Optional.of(pairMapper);
}
}Row mapper factories may be registered similar to regular row mappers:
jdbi.registerRowMapper(new PairMapperFactory());
try (Handle handle = jdbi.open()) {
List<Pair<String, String>> configPairs = handle
.createQuery("SELECT key, value FROM config")
.mapTo(new GenericType<Pair<String, String>>() {})
.list();
}
The GenericType utility class is discussed in Working with Generic Types.
|
7.2. Column Mappers
ColumnMapper is a functional interface, which maps a column from the current row of a JDBC ResultSet to a mapped type.
Since ColumnMapper is a functional interface, they can be provided inline to a query using a lambda expression:
List<Money> amounts = handle
.select("SELECT amount FROM transactions WHERE account_id = ?", accountId)
.map((rs, col, ctx) -> Money.parse(rs.getString(col))) (1)
.list();Whenever a column mapper is used to map rows, only the first column of each row is mapped.
Column mappers may be defined as classes, which allows for re-use:
public class MoneyMapper implements ColumnMapper<Money> {
public Money map(ResultSet r, int columnNumber, StatementContext ctx) throws SQLException {
return Money.parse(r.getString(columnNumber));
}
}List<Money> amounts = handle
.select("SELECT amount FROM transactions WHERE account_id = ?", accountId)
.map(new MoneyMapper())
.list();This ColumnMapper is equivalent to the lambda mapper above, but more explicit.
7.2.1. ColumnMappers registry
Column mappers may be registered for specific types. This simplifies usage, requiring only that you specify what type you want to map to. Jdbi automatically looks up the mapper from the registry, and uses it.
jdbi.registerColumnMapper(Money.class,
(rs, col, ctx) -> Money.parse(rs.getString(col)));
List<Money> amounts = jdbi.withHandle(handle ->
handle.select("SELECT amount FROM transactions WHERE account_id = ?", accountId)
.mapTo(Money.class)
.list());A mapper which implements ColumnMapper with an explicit mapped type (such as
the MoneyMapper class in the previous section) may be registered without
specifying the mapped type:
handle.registerColumnMapper(new MoneyMapper());When this method is used, Jdbi inspects the generic class signature of the mapper to automatically discover the mapped type.
It is possible to register more than one mapper for any given type. When this happens, the last-registered mapper for a given type takes precedence. This permits optimizations, like registering a "default" mapper for some type, while allowing that default mapper to be overridden with a different one when appropriate.
Out of the box, column mappers are registered for the following types:
-
Primitives:
boolean,byte,short,int,long,char,float, anddouble -
java.lang:
Boolean,Byte,Short,Integer,Long,Character,Float,Double,String, andEnum(stored as the enum value’s name by default) -
java.math:
BigDecimal -
byte[]arrays (e.g. for BLOB or VARBINARY columns) -
java.net:
InetAddress,URL, andURI -
java.sql:
Timestamp -
java.time:
Instant,LocalDate,LocalDateTime,LocalTime,OffsetDateTime,ZonedDateTime, andZoneId -
java.util:
UUID -
java.util.Collectionand Java arrays (for array columns). Some additional setup may be required depending on the type of array element—see SQL Arrays.
| The binding and mapping method for enum values can be controlled via the Enums config, as well as the EnumByName and EnumByOrdinal annotations. |
7.2.2. ColumnMapperFactory
A ColumnMapperFactory can produce column mappers for arbitrary types.
Implementing a factory might be preferable to a regular column mapper if:
-
The mapper class is generic, and could apply to multiple mapped types.
-
The type being mapped is generic, and/or the mapper could be composed of other registered mappers.
-
You want to bundle multiple mappers into a single class.
Let’s create a mapper factory for Optional<T> as an example. The factory
should produce a ColumnMapper<Optional<T>> for any T, provided a column
mapper is registered for T.
Let’s take this one step at a time:
public class OptionalColumnMapperFactory implements ColumnMapperFactory {
public Optional<ColumnMapper<?>> build(Type type, ConfigRegistry config) {
// ...
}
}The build method accepts a mapped type, and a config registry. It may return
Optional.of(someMapper) if it knows how to map that type, or
Optional.empty() otherwise.
First, we check whether the mapped type is an Optional:
if (!Optional.class.equals(GenericTypes.getErasedType(type))) {
return Optional.empty();
}
The GenericTypes utility class is discussed in Working with Generic Types.
|
Next, extract the T generic parameter from the mapped type:
Type t = GenericTypes.resolveType(Optional.class.getTypeParameters()[0], type);The expression Optional.class.getTypeParameters()[0] gives the type variable
T.
We use resolveType() to resolve the type of T in the context of the mapped
type.
Now that we have the type of T, we can look up a column mapper for that type
from the ColumnMappers config class, through the config registry:
ColumnMapper<?> tMapper = config.get(ColumnMappers.class)
.findFor(embeddedType)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for parameter " + embeddedType + " of type " + type));The config registry is a locator for config classes. So when we call
config.get(ColumnMappers.class), we get back a ColumnMappers instance with
the current column mapper configuration.
Next we call ColumnMappers.findFor() to get the column mapper for the embedded
type.
You may have noticed that although this method can return Optional, we’re
throwing an exception if we can’t find a mapper for the embedded type. We’ve
found this to be a best practice: return Optional.empty() if the factory knows
nothing about the mapped type (Optional, in this case). If it knows the mapped
type but is missing some configuration to make it work (e.g. no mapper
registered for tye T parameter) it is more helpful to throw an exception with
an informative message, so users can diagnose why the mapper is not working as
expected.
|
Finally, we construct the column mapper for optionals, and return it:
ColumnMapper<?> optionalMapper = (rs, col, ctx) ->
Optional.ofNullable(tMapper.map(rs, col, ctx));
return Optional.of(optionalMapper);Here is the factory class all together:
public class OptionalColumnMapperFactory implements ColumnMapperFactory {
public Optional<ColumnMapper<?>> build(Type type, ConfigRegistry config) {
if (!Optional.class.equals(GenericTypes.getErasedType(type))) {
return Optional.empty();
}
Type t = GenericTypes.resolveType(Optional.class.getTypeParameters()[0], type);
ColumnMapper<?> tMapper = config.get(ColumnMappers.class)
.findFor(t)
.orElseThrow(() -> new NoSuchMapperException(
"No column mapper registered for parameter " + t + " of type " + type));
ColumnMapper<?> optionalMapper = (rs, col, ctx) -> Optional.ofNullable(tMapper.map(rs, col, ctx));
return Optional.of(optionalMapper);
}
}Column mapper factories may be registered similar to regular column mappers:
jdbi.registerColumnMapper(new OptionalColumnMapperFactory());
try (Handle handle = jdbi.open()) {
List<Optional<String>> middleNames = handle
.createQuery("SELECT middle_name FROM contacts")
.mapTo(new GenericType<Optional<String>>() {})
.list();
}
The GenericType utility class is discussed in Working with Generic Types.
|
7.3. Primitive Mapping
All Java primitive types have default mappings to their corresponding JDBC types. Generally, Jdbi will automatically perform boxing and unboxing as appropriate when it encounters wrapper types.
By default, SQL null mapped to a primitive type will adopt the Java default value.
This may be disabled by configuring
jdbi.getConfig(ColumnMappers.class).setCoalesceNullPrimitivesToDefaults(false).
7.4. Immutables Mapping
Immutables value objects may be mapped, see the Immutables section for details.
7.5. Freebuilder Mapping
Freebuilder value objects may be mapped, see the Freebuilder section for details.
7.6. Reflection Mappers for Beans and POJOs
Jdbi provides a number of reflection-based mappers out of the box which treat column names as attributes. The different mappers can be used to map values onto
-
Java Bean properties (
BeanMapper) -
Class fields (
FieldMapper) -
Constructor parameters (
ConstructorMapper)
There is also an equivalent mapper for Kotlin classes that supports constructor arguments and class properties.
Reflective mappers are snake_case aware and will automatically match up these columns to camelCase field/argument/property names.
7.6.1. Supported property annotations
Reflection mappers support the following annotations.
Unless otherwise noted, all annotations are supported on bean getters and setters for the BeanMapper, constructor parameters for the ConstructorMapper and bean fields for the FieldMapper.
-
@ColumnName allows explicit naming of the column that is mapped to the specific attribute.
-
@Nested for nested beans. Without this annotation, any attribute is treated as mappable from a single column. This annotation creates a mapper for the nested bean. There is a limitation that only one type of mapper can be nested at a time;
BeanMapperwill create anotherBeanMapper,ConstructorMapperwill create anotherConstructorMapperetc. @Nested supports an optional prefix for all attributes in the nested bean (@Nested("prefix")). -
@PropagateNullon a given attribute propagates a null value for a specific attribute up. So if the attribute or column is null, the whole bean will be discarded and a null value will be used instead of the bean itself. This annotation can also be used on the bean class with a column name that must be present in the result set. When used on an attribute, no value must be set. -
@NullableforConstructorMapperarguments. If no column is mapped onto a specific constructor argument, don’t fail but usenullas value. -
@JdbiProperty(map=false)allows configuring whether a discovered property is mapped in results. Turn themapvalue off, and the property discovery mechanism will ignore it. This used to be called@Unmappable.
The @ColumnName annotation only applies while mapping SQL data into Java objects.
When binding object properties (e.g. with bindBean()), bind the property name (:id) rather than the column name (:user_id).
|
Using @Nullable annotations
Jdbi accepts any annotation that is named Nullable to mark a field or method as nullable.
These are popular choices:
-
jakarta.annotation.Nullable— jakarta annotation-api -
javax.annotation.Nullable— findbugs jsr305 -
edu.umd.cs.findbugs.annotations.Nullable— Spotbugs annotations -
org.jetbrains.annotations.Nullable— Jetbrains annotations -
org.checkerframework.checker.nullness.qual.Nullable— checker framework -
org.springframework.lang.Nullable— Spring Framework
To allow Jdbi to discover the @Nullable annotation at runtime, it must use RetentionPolicy.RUNTIME.
When in doubt, prefer the Jakarta variant!.
|
7.6.2. ConstructorMapper
ConstructorMapper assigns columns to constructor parameters by
name. If the java compiler stores method parameter names in the java
classes (using the -parameters flag on the compiler — see also
Compiling with Parameter Names), the constructor mapper will use
these names to select columns.
public User(int id, String name) {
this.id = id;
this.name = name;
}Otherwise, the names can be explictly set with the @ColumnName annotation on each constructor parameter:
public User(@ColumnName("id") int id, @ColumnName("name") String name) {
this.id = id;
this.name = name;
}The standard Java Bean @ConstructorProperties annotation can also be used:
@ConstructorProperties({"id", "name"})
public User(int id, String name) {
this.id = id;
this.name = name;
}
Lombok’s @AllArgsConstructor annotation generates the
@ConstructorProperties annotation for you.
|
Register a constructor mapper for your mapped class using the factory() or of()
methods:
handle.registerRowMapper(ConstructorMapper.factory(User.class));
Set<User> userSet = handle.createQuery("SELECT * FROM \"user\" ORDER BY id ASC")
.mapTo(User.class)
.collect(Collectors.toSet());
assertThat(userSet).hasSize(4);The constructor parameter names "id", "name" match the database column names and as such no custom mapper code is required at all.
Constructor mappers can be configured with a column name prefix for each mapped
constructor parameter. This can help to disambiguate mapping joins, e.g. when
two mapped classes have identical property names (like id or name):
handle.registerRowMapper(ConstructorMapper.factory(Contact.class, "c"));
handle.registerRowMapper(ConstructorMapper.factory(Phone.class, "p"));
handle.registerRowMapper(JoinRowMapper.forTypes(Contact.class, Phone.class);
List<JoinRow> contactPhones = handle.select("SELECT " +
"c.id cid, c.name cname, " +
"p.id pid, p.name pname, p.number pnumber " +
"FROM contacts c LEFT JOIN phones p ON c.id = p.contact_id")
.mapTo(JoinRow.class)
.list();Typically, the mapped class will have a single constructor. If it has multiple constructors, Jdbi will pick one based on these rules:
-
First, use the constructor annotated with
@JdbiConstructor, if any. -
Next, use the constructor annotated with
@ConstructorProperties, if any. -
Otherwise, throw an exception that Jdbi does not know which constructor to use.
For legacy column names that don’t match up to property names, use the @ColumnName annotation to provide an exact column name.
public User(@ColumnName("user_id") int id, String name) {
this.id = id;
this.name = name;
}Nested constructor-injected types can be mapped using the @Nested annotation:
public class User {
public User(int id,
String name,
@Nested Address address) {
// ...
}
}
public class Address {
public Address(String street,
String city,
String state,
String zip) {
// ...
}
}handle.registerRowMapper(ConstructorMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, street, city, state, zip FROM users")
.mapTo(User.class)
.list();The @Nested annotation has an optional value() attribute, which can be used to apply a column name prefix to each nested constructor parameter:
public User(int id,
String name,
@Nested("addr") Address address) {
// ...
}handle.registerRowMapper(ConstructorMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, addr_street, addr_city, addr_state, addr_zip FROM users")
.mapTo(User.class)
.list();By default, ConstructorMapper expects the result set to contain columns to map every constructor parameter, and will throw an exception if any parameters cannot be mapped.
Parameters annotated @Nullable (see Using @Nullable annotations) may be omitted from the result set, in which
ConstructorMapper will pass null to the constructor for that parameter.
public class User {
public User(int id,
String name,
@Nullable String passwordHash,
@Nullable @Nested Address address) {
// ...
}
}In this example, the id and name columns must be present in the result set, but passwordHash and address are optional.
If they are present, they will be mapped.
7.6.3. BeanMapper
BeanMapper assigns columns to bean properties. This mapper uses the standard Java Bean conventions.
public class UserBean {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
The standard bean convention requires that the setter returns a void value. The popular "builder pattern" setter
convention of returning the bean itself does not work with the standard Java Bean convention and the setter will not be found. This is a common source of problems when using the BeanMapper.
|
Register a bean mapper for your mapped class, using the factory() method:
handle.registerRowMapper(BeanMapper.factory(UserBean.class));
List<UserBean> users = handle
.createQuery("select id, \"name\" from \"user\"")
.mapTo(UserBean.class)
.list();Alternatively, call mapToBean() instead of registering a bean mapper:
List<UserBean> users = handle
.createQuery("select id, \"name\" from \"user\"")
.mapToBean(UserBean.class)
.list();Or use map with an instance:
List<UserBean> users = handle
.createQuery("select id, \"name\" from \"user\"")
.map(BeanMapper.of(UserBean.class))
.list();Bean mappers can be configured with a column name prefix for each mapped
property. This can help to disambiguate mapping joins, e.g. when two mapped
classes have identical property names (like id or name):
handle.registerRowMapper(BeanMapper.factory(ContactBean.class, "c"));
handle.registerRowMapper(BeanMapper.factory(PhoneBean.class, "p"));
handle.registerRowMapper(JoinRowMapper.forTypes(ContactBean.class, PhoneBean.class));
List<JoinRow> contactPhones = handle.select("select "
+ "c.id cid, c.\"name\" cname, "
+ "p.id pid, p.\"name\" pname, p.\"number\" pnumber "
+ "from contacts c left join phones p on c.id = p.contact_id")
.mapTo(JoinRow.class)
.list();For legacy column names that don’t match up to property names, use the @ColumnName annotation to provide an exact column name.
public class User {
private int id;
@ColumnName("user_id")
public int getId() { return id; }
public void setId(int id) { this.id = id; }
}The @ColumnName annotation can be placed on either the getter or setter method. If conflicting annotations exist, then Annotations on the setter are preferred.
Nested Java Bean types can be mapped using the @Nested annotation:
public class User {
private int id;
private String name;
private Address address;
// ... (getters and setters)
@Nested (1)
public Address getAddress() { ... }
public void setAddress(Address address) { ... }
}
public class Address {
private String street;
private String city;
private String state;
private String zip;
// ... (getters and setters)
}| 1 | The @Nested annotation can be placed on either the getter or setter method. The setter is preferred. |
handle.registerRowMapper(BeanMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, street, city, state, zip FROM users")
.mapTo(User.class)
.list();The @Nested annotation has an optional value() attribute, which can be used to apply a column name prefix to each nested bean property:
@Nested("addr")
public Address getAddress() { ... }handle.registerRowMapper(BeanMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, addr_street, addr_city, addr_state, addr_zip FROM users")
.mapTo(User.class)
.list();| @Nested properties are left unmodified (i.e. null) if the result set has no columns matching any properties of the nested object. |
7.6.4. FieldMapper
FieldMapper uses reflection to map database columns directly to object fields (including private fields).
public class User {
public int id;
public String name;
}Register a field mapper for your mapped class, using the factory() method:
handle.registerRowMapper(FieldMapper.factory(User.class));
List<UserBean> users = handle
.createQuery("SELECT id, name FROM user")
.mapTo(User.class)
.list();Field mappers can be configured with a column name prefix for each mapped
field. This can help to disambiguate mapping joins, e.g. when two mapped
classes have identical property names (like id or name):
handle.registerRowMapper(FieldMapper.factory(Contact.class, "c"));
handle.registerRowMapper(FieldMapper.factory(Phone.class, "p"));
handle.registerRowMapper(JoinRowMapper.forTypes(Contact.class, Phone.class);
List<JoinRow> contactPhones = handle.select(
"SELECT " +
"c.id cid, c.name cname, " +
"p.id pid, p.name pname, p.number pnumber " +
"FROM contacts c LEFT JOIN phones p ON c.id = p.contact_id")
.mapTo(JoinRow.class)
.list();For legacy column names that don’t match up to field names, use the @ColumnName annotation to provide an exact column name:
public class User {
@ColumnName("user_id")
public int id;
public String name;
}Nested field-mapped types can be mapped using the @Nested annotation:
public class User {
public int id;
public String name;
@Nested
public Address address;
}
public class Address {
public String street;
public String city;
public String state;
public String zip;
}handle.registerRowMapper(FieldMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, street, city, state, zip FROM users")
.mapTo(User.class)
.list();The @Nested annotation has an optional value() attribute, which can be used to apply a column name prefix to each nested field:
public class User {
public int id;
public String name;
@Nested("addr")
public Address address;
}handle.registerRowMapper(FieldMapper.factory(User.class));
List<User> users = handle
.select("SELECT id, name, addr_street, addr_city, addr_state, addr_zip FROM users")
.mapTo(User.class)
.list();| @Nested fields are left unmodified (i.e. null) if the result set has no columns matching any fields of the nested object. |
7.7. Map.Entry Mapping
Out of the box, Jdbi registers a RowMapper<Map.Entry<K,V>>. Since each row in
the result set is a Map.Entry<K,V>, the entire result set can be easily
collected into a Map<K,V> (or Guava’s Multimap<K,V>).
| A mapper must be registered for both the key and value type. |
Join rows can be gathered into a map result by specifying the generic map signature:
CharSequence sql = "select u.id u_id, u.name u_name, p.id p_id, p.phone p_phone "
+ "from \"user\" u left join phone p on u.id = p.user_id";
Map<User, Phone> map = h.createQuery(sql)
.registerRowMapper(ConstructorMapper.factory(User.class, "u"))
.registerRowMapper(ConstructorMapper.factory(Phone.class, "p"))
.collectInto(new GenericType<Map<User, Phone>>() {});In the preceding example, the User mapper uses the "u" column name prefix, and
the Phone mapper uses "p". Since each mapper only reads columns with the
expected prefix, the respective id columns are unambiguous.
A unique index (e.g. by ID column) can be obtained by setting the key column name:
Map<Integer, User> map = h.createQuery("select * from \"user\"")
.setMapKeyColumn("id")
.registerRowMapper(ConstructorMapper.factory(User.class))
.collectInto(new GenericType<Map<Integer, User>>() {});Set both the key and value column names to gather a two-column query into a map result:
Map<String, String> map = h.createQuery("select \"key\", \"value\" from config")
.setMapKeyColumn("key")
.setMapValueColumn("value")
.collectInto(new GenericType<Map<String, String>>() {});All the above examples assume a one-to-one key/value relationship. What if there is a one-to-many relationship?
Google Guava provides a Multimap type, which supports mapping multiple
values per key.
First, follow the instructions in the Google Guava section to install the GuavaPlugin into Jdbi.
Then, simply ask for a Multimap instead of a Map:
String sql = "select u.id u_id, u.name u_name, p.id p_id, p.phone p_phone "
+ "from \"user\" u left join phone p on u.id = p.user_id";
Multimap<User, Phone> map = h.createQuery(sql)
.registerRowMapper(ConstructorMapper.factory(User.class, "u"))
.registerRowMapper(ConstructorMapper.factory(Phone.class, "p"))
.collectInto(new GenericType<Multimap<User, Phone>>() {});The collectInto() method is worth explaining. When you call it, several things
happen behind the scenes:
-
Consult the JdbiCollectors registry to obtain a CollectorFactory which supports the given container type.
-
Next, ask that
CollectorFactoryto extract the element type from the container type signature. In the above example, the element type ofMultimap<User,Phone>isMap.Entry<User,Phone>. -
Obtain a mapper for that element type from the mapping registry.
-
Obtain a Collector for the container type from the
CollectorFactory. -
Finally, return
map(elementMapper).collect(collector).
| If the lookup for the collector factory, element type, or element mapper fails, an exception is thrown. |
Jdbi can be enhanced to support arbitrary container types.
8. Codecs
A codec is a replacement for registering an argument and a column mapper for a type. It is responsible for serializing a typed value into a database column and creating a type from a database column.
Codecs are collected in a codec factory, which can be registered with the registerCodecFactory convenience method.
// register a single codec
jdbi.registerCodecFactory(CodecFactory.forSingleCodec(type, codec));
// register a few codecs
jdbi.registerCodecFactory(CodecFactory.builder()
// register a codec by qualified type
.addCodec(QualifiedType.of(Foo.class), codec1)
// register a codec by direct java type
.addCodec(Foo.class, codec2)
// register a codec by generic type
.addCodec(new GenericType<Set<Foo>>() {}. codec3)
.build());
// register many codecs
Map<QualifiedType<?>, Codec<?>> codecs = ...
jdbi.registerCodecFactory(new CodecFactory(codecs));Codec example:
public class Counter {
private int count = 0;
public Counter() {}
public int nextValue() {
return count++;
}
private Counter setValue(int value) {
this.count = value;
return this;
}
private int getValue() {
return count;
}
/**
* Codec to persist a counter to the database and restore it back.
*/
public static class CounterCodec implements Codec<Counter> {
@Override
public ColumnMapper<Counter> getColumnMapper() {
return (r, idx, ctx) -> new Counter().setValue(r.getInt(idx));
}
@Override
public Function<Counter, Argument> getArgumentFunction() {
return counter -> (idx, stmt, ctx) -> stmt.setInt(idx, counter.getValue());
}
}
}Jdbi core API:
// register the codec with JDBI
jdbi.registerCodecFactory(CodecFactory.forSingleCodec(COUNTER_TYPE, new CounterCodec()));
// store object
int result = jdbi.withHandle(h -> h.createUpdate("INSERT INTO counters (id, \"value\") VALUES (:id, :value)")
.bind("id", counterId)
.bindByType("value", counter, COUNTER_TYPE)
.execute());
// load object
Counter restoredCounter = jdbi.withHandle(h -> h.createQuery("SELECT \"value\" from counters where id = :id")
.bind("id", counterId)
.mapTo(COUNTER_TYPE).first());SQL Object API uses the codecs transparently:
// SQL object dao
public interface CounterDao {
@SqlUpdate("INSERT INTO counters (id, \"value\") VALUES (:id, :value)")
int storeCounter(@Bind("id") String id, @Bind("value") Counter counter);
@SqlQuery("SELECT \"value\" from counters where id = :id")
Counter loadCounter(@Bind("id") String id);
}
// register the codec with JDBI
jdbi.registerCodecFactory(CodecFactory.forSingleCodec(COUNTER_TYPE, new CounterCodec()));
// store object
int result = jdbi.withExtension(CounterDao.class, dao -> dao.storeCounter(counterId, counter));
// load object
Counter restoredCounter = jdbi.withExtension(CounterDao.class, dao -> dao.loadCounter(counterId));8.1. Resolving Types
By using the TypeResolvingCodecFactory from the guava module, it is possible to use codecs that are registered for subclasses or interface types for concrete classes. This is necessary to e.g. map Auto Value generated classes to database columns.
In the following example, there is only a codec for Value<String> registered, but the code uses beans and classes that are concrete implementations (StringBean contains a StringValue and StringValue implements the Value<String> interface). The TypeResolvingCodecFactory will inspect the types to find a codec for an interface or superclass if no perfect match can be found.
// SQL object dao using concrete types
public interface DataDao {
@SqlUpdate("INSERT INTO data (id, \"value\") VALUES (:bean.id, :bean.value)")
int storeData(@BindBean("bean") StringBean bean);
@SqlUpdate("INSERT INTO data (id, \"value\") VALUES (:id, :value)")
int storeData(@Bind("id") String id, @Bind("value") StringValue data);
@SqlQuery("SELECT \"value\" from data where id = :id")
StringValue loadData(@Bind("id") String id);
}
// generic type representation
public static final QualifiedType<Value<String>> DATA_TYPE = QualifiedType.of(new GenericType<Value<String>>() {});
public static class DataCodec implements Codec<Value<String>> {
@Override
public ColumnMapper<Value<String>> getColumnMapper() {
return (r, idx, ctx) -> new StringValue(r.getString(idx));
}
@Override
public Function<Value<String>, Argument> getArgumentFunction() {
return data -> (idx, stmt, ctx) -> stmt.setString(idx, data.getValue());
}
}
// value interface
public interface Value<T> {
T getValue();
}
// bean using concrete types, not interface types.
public static class StringBean implements Bean<Value<String>> {
private final String id;
private final StringValue value;
public StringBean(String id, StringValue value) {
this.id = id;
this.value = value;
}
@Override
public String getId() {
return id;
}
@Override
public StringValue getValue() {
return value;
}
}9. Results
A number of operations return data from the database through a JDBC ResultSet:
-
Query operations
-
The Update#executeAndReturnGeneratedKeys and PreparedBatch#executeAndReturnGeneratedKeys methods
-
Metadata operations
The JDBC ResultSet class can do simple mapping to Java primitives and built in classes, but the API is often cumbersome to use.
Jdbi offers many ways to process and map these responses onto other objects using configurable mapping, including the ability to register custom mappers for rows and columns.
A ColumnMapper converts a single column’s value into a Java object. It can be used as a RowMapper if there is only one column present, or it can be used to build more complex RowMapper types.
The mapper is selected based on the declared result type of your query.
Jdbi iterates over the rows in the ResultSet and presents the mapped results to you in a container such as a List, Stream, Optional, or Iterator.
public static class User {
final int id;
final String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
@BeforeEach
public void setUp() {
handle = h2Extension.getSharedHandle();
handle.execute("CREATE TABLE \"user\" (id INTEGER PRIMARY KEY AUTO_INCREMENT, \"name\" VARCHAR)");
for (String name : Arrays.asList("Alice", "Bob", "Charlie", "Data")) {
handle.execute("INSERT INTO \"user\" (\"name\") VALUES (?)", name);
}
}
@Test
public void findBob() {
User u = findUserById(2).orElseThrow(() -> new AssertionError("No user found"));
assertThat(u.id).isEqualTo(2);
assertThat(u.name).isEqualTo("Bob");
}
public Optional<User> findUserById(long id) {
RowMapper<User> userMapper =
(rs, ctx) -> new User(rs.getInt("id"), rs.getString("name"));
return handle.createQuery("SELECT * FROM \"user\" WHERE id=:id")
.bind("id", id)
.map(userMapper)
.findFirst();
}Jdbi operations that involve a ResultSet are defined and executed in multiple steps:
List<User> users = handle.createQuery("SELECT * FROM users WHERE department = :department") (1)
.bind("department", departmentId) (2)
.mapTo(User.class) (3)
.list(); (4)| 1 | create a Statement that implements ResultBearing |
| 2 | execute methods on the statement in builder-style which return the same statement type |
| 3 | execute a method defined by ResultBearing that returns a ResultIterable |
| 4 | execute a terminal method on ResultIterable that returns the result |
The ResultBearing and ResultIterable interfaces define all data mapping operations that Jdbi offer.
9.1. ResultBearing
The ResultBearing interface represents the result set of a database operation, which has not been mapped to any particular result type.
ResultBearing contains two major groups of operations:
-
latent operations that return a ResultIterable. These operations map the unmapped result of an operation to a specific type. They require a method on the ResultIterable to be called to execute the actual operation
-
terminal operations that collect, scan or reduce the result set. Calling one of these methods, executes the actual operation and returns a result.
9.1.1. Mapping result types with latent operations
These operations create a map from the data returned by the database onto java objects. This mapping is described in multiple ways:
-
map()operations using a RowMapper, ColumnMapper or RowViewMapper instance. -
mapTo()operations using a type definition. The matching mapper is retrieved from the RowMappers registry. Supports regular Java Types, Generic Types and Qualified Types. -
mapToMap()operations where the key is the (lower-cased) column name and the value is the column value. Supports regular Java Types, Generic Types and Qualified Types for the values. The value mapper is retrieved from the RowMappers registry. -
mapToBean()maps to a mutable bean instance with that provides setters to set values. For each column name, the corresponding setter is called.
This is the most common use case when using the ResultBearing interface:
ResultIterable<User> resultIterable = handle
.createQuery("SELECT * from users")
.mapTo(User.class);
List<User> users = resultIterable.list();TODO:
-
Describe terminal operations on the ResultBearing
-
reduceRows
-
RowView
-
-
reduceResultSet
-
collectInto e.g. with a GenericType token. Implies a mapTo() and a collect() in one operation. e.g. collectInto(new GenericType<List<User>>(){}) is the same as mapTo(User.class).collect(toList())
-
Provide list of container types supported out of the box
9.2. ResultIterable
A ResultIterable represents a result set which has been mapped to a specific type, e.g. a ResultIterable<User>.
Almost all operations on the ResultIterable interface are terminal operations. When they finish, they close and release all resources, especially the ResultSet and PreparedStatement objects.
See Statement resource management for more details on how resources are released and should be managed.
The stream() and iterator() operations are not terminal. They return objects that need to be managed by the caller. See the Resources with Streams and Iterators chapter for more details.
TODO:
-
one(), list(), first(), findOne(), findFirst()
-
mention filter, map as non-terminals
-
collect, reduce
-
callback consumers for iterator and stream
-
ResultIterable.forEach, forEachWithCount
9.2.1. Finding a Single Result
ResultIterable.one() returns the only row in the result set. If zero or
multiple rows are encountered, it will throw IllegalStateException.
ResultIterable.findOne() returns an Optional<T> of the only row in the
result set, or Optional.empty() if no rows are returned.
ResultIterable.first() returns the first row in the result set. If zero
rows are encountered, IllegalStateException is thrown.
ResultIterable.findFirst() returns an Optional<T> of the first row, if
any.
9.2.2. Stream
Stream integration allows you to use a RowMapper to adapt a ResultSet into the Java Streams framework. The stream will lazily fetch rows from the database as necessary.
The stream() method returns a Stream<T>. This is not a terminal operation and the stream must be closed to release any database resources held. See Resources with Streams and Iterators for more details.
The withStream() and useStream() methods pass the Stream into a callback.
handle.createQuery("SELECT id, name FROM user ORDER BY id ASC")
.map(new UserMapper())
.useStream(stream -> {
Optional<String> first = stream
.filter(u -> u.id > 2)
.map(u -> u.name)
.findFirst();
assertThat(first).contains("Charlie");
});These methods handle closing the stream for the caller. The withStream() method allows passing a result back to the caller, useStream() only executed the code in the callback.
9.2.3. List
#list emits a List<T>. This necessarily buffers all results in memory.
List<User> users =
handle.createQuery("SELECT id, name FROM user")
.map(new UserMapper())
.list();9.2.4. Collectors
#collect takes a Collector<T, ?, R> that builds a resulting collection
R<T>. The java.util.stream.Collectors class has a number of interesting
Collector implementations to start with.
You can also write your own custom collectors. For example, to accumulate found rows into a Map:
h.execute("INSERT INTO something (id, name) VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Chuckles')");
Map<Integer, Something> users = h.createQuery("SELECT id, name FROM something")
.mapTo(Something.class)
.collect(Collector.of(HashMap::new, (accum, item) -> {
accum.put(item.getId(), item); // Each entry is added into an accumulator map
}, (l, r) -> {
l.putAll(r); // While jdbi does not process rows in parallel,
return l; // the Collector contract encourages writing combiners
}, Characteristics.IDENTITY_FINISH));9.2.5. Reduction
#reduce provides a simplified Stream#reduce. Given an identity starting value and a BiFunction<U, T, U> it will repeatedly combine U until only a single remains, and then return that.
9.2.6. ResultSetScanner
The ResultSetScanner interface accepts a lazily-provided ResultSet and produces the result Jdbi returns from statement execution.
Most of the above operations are implemented in terms of ResultSetScanner. The Scanner has ownership of the ResultSet and may advance or seek it.
The return value ends up being the final result of statement execution.
Most users should prefer using the higher level result collectors described above, but someone’s gotta do the dirty work.
9.3. Joins
Joining multiple tables together is a very common database task. It is also where the mismatch between the relational model and Java’s object model starts to rear its ugly head.
Here we present a couple of strategies for retrieving results from more complicated rows.
Consider a contact list app as an example. The contact list contains any number of contacts. Contacts have a name, and any number of phone numbers. Phone numbers have a type (e.g. home, work) and a phone number:
class Contact {
Long id;
String name;
List<Phone> phones = new ArrayList<>();
void addPhone(Phone phone) {
phones.add(phone);
}
}
class Phone {
Long id;
String type;
String phone;
}We’ve left out getters, setters, and access modifiers for brevity.
Since we’ll be reusing the same queries, we’ll define them as constants now:
static final String SELECT_ALL = "SELECT contacts.id c_id, name c_name, "
+ "phones.id p_id, type p_type, phones.phone p_phone "
+ "FROM contacts LEFT JOIN phones ON contacts.id = phones.contact_id "
+ "order by c_name, p_type ";
static final String SELECT_ONE = SELECT_ALL + "where phones.id = :id";Note that we’ve given aliases (e.g. c_id, p_id) to distinguish columns of
the same name (id) from different tables.
Jdbi provides a few different APIs for dealing with joined data.
9.3.1. ResultBearing.reduceRows()
The
"ResultBearing.reduceRows(U, BiFunction)"
method accepts an accumulator seed value and a lambda function. For each row in
the result set, Jdbi calls the lambda with the current accumulator value and a
RowView over the current row of the
result set. The value returned for each row becomes the input accumulator
passed in for the next row. After the last row has been processed,
reducedRows() returns the last value returned from the lambda.
List<Contact> contacts = handle.createQuery(SELECT_ALL)
.registerRowMapper(BeanMapper.factory(Contact.class, "c"))
.registerRowMapper(BeanMapper.factory(Phone.class, "p")) (1)
.reduceRows(new LinkedHashMap<Long, Contact>(), (2)
(map, rowView) -> {
Contact contact = map.computeIfAbsent( (3)
rowView.getColumn("c_id", Long.class),
id -> rowView.getRow(Contact.class));
if (rowView.getColumn("p_id", Long.class) != null) { (4)
contact.addPhone(rowView.getRow(Phone.class));
}
return map; (5)
})
.values() (6)
.stream()
.collect(toList()); (7)| 1 | Register row mappers for Contact and Phone. Note the "c" and "p"
arguments used—these are column name prefixes. By registering mappers with
prefixes, the Contact mapper will only map the c_id and c_name
columns, whereas the Phone mapper will only map p_id, p_type, and
p_phone. |
| 2 | Use an empty LinkedHashMap
as the accumulator seed, mapped by contact ID. LinkedHashMap is a good
accumulator when selecting multiple master records, since it has fast
storage and lookup while preserving insertion order (which helps honor
ORDER BY clauses). If ordering is unimportant, a HashMap would also
suffice. |
| 3 | Load the Contact from the accumulator if we already have it; otherwise,
initialize it through the RowView. |
| 4 | If p_id column is not null, load the phone number from the current row
and add it to the current contact. |
| 5 | Return the input map (now sporting an additional contact and/or phone) as the accumulator for the next row. |
| 6 | At this point, all rows have been read into memory, and we don’t need the
contact ID keys. So we call Map.values() to get a Collection<Contact>. |
| 7 | Collect the contacts into a List<Contact>. |
Alternatively, the ResultBearing.reduceRows(RowReducer) variant accepts a RowReducer and returns a stream of reduced elements.
For simple master-detail joins, the ResultBearing.reduceRows(BiConsumer<Map<K,V>,RowView>) method makes it easy to reduce these joins into a stream of master elements.
Adapting the example above:
List<Contact> contacts = handle.createQuery(SELECT_ALL)
.registerRowMapper(BeanMapper.factory(Contact.class, "c"))
.registerRowMapper(BeanMapper.factory(Phone.class, "p"))
.reduceRows((Map<Long, Contact> map, RowView rowView) -> { (1)
Contact contact = map.computeIfAbsent(
rowView.getColumn("c_id", Long.class),
id -> rowView.getRow(Contact.class));
if (rowView.getColumn("p_id", Long.class) != null) {
contact.addPhone(rowView.getRow(Phone.class));
}
(2)
})
.collect(toList()); (3)| 1 | The lambda receives a map where result objects will be stored, and a
RowView. The map is a LinkedHashMap, so the result stream will
yield the result objects in the same order they were inserted. |
| 2 | No return statement needed. The same map is reused on every row. |
| 3 | This reduceRows() invocation produces a Stream<Contact> (i.e. from
map.values().stream(). In this example, we collect the elements into a
list, but we could call any Stream method here. |
You may be wondering about the getRow() and getColumn() calls to rowView.
When you call rowView.getRow(SomeType.class), RowView looks up the
registered row mapper for SomeType, and uses it to map the current row to a
SomeType object.
Likewise, when you call rowView.getColumn("my_value", MyValueType.class),
RowView looks up the registered column mapper for MyValueType, and uses it
to map the my_value column of the current row to a MyValueType object.
Now let’s do the same thing, but for a single contact:
Optional<Contact> contact = handle.createQuery(SELECT_ONE)
.bind("id", contactId)
.registerRowMapper(BeanMapper.factory(Contact.class, "c"))
.registerRowMapper(BeanMapper.factory(Phone.class, "p"))
.reduceRows(LinkedHashMapRowReducer.<Long, Contact> of((map, rowView) -> {
Contact contact = map.orElseGet(() -> rowView.getRow(Contact.class));
if (rowView.getColumn("p_id", Long.class) != null) {
contact.addPhone(rowView.getRow(Phone.class));
}
})
.findFirst();9.3.2. ResultBearing.reduceResultSet()
ResultBearing.reduceResultSet()
is a low-level API similar to reduceRows(), except it provides direct access
to the JDBC ResultSet instead of a RowView for each row.
This method can provide superior performance compared to reduceRows(), at the
expense of verbosity:
List<Contact> contacts = handle.createQuery(SELECT_ALL)
.reduceResultSet(new LinkedHashMap<Long, Contact>(),
(acc, resultSet, ctx) -> {
long contactId = resultSet.getLong("c_id");
Contact contact;
if (acc.containsKey(contactId)) {
contact = acc.get(contactId);
} else {
contact = new Contact();
acc.put(contactId, contact);
contact.setId(contactId);
contact.setName(resultSet.getString("c_name"));
}
long phoneId = resultSet.getLong("p_id");
if (!resultSet.wasNull()) {
Phone phone = new Phone();
phone.setId(phoneId);
phone.setType(resultSet.getString("p_type"));
phone.setPhone(resultSet.getString("p_phone"));
contact.addPhone(phone);
}
return acc;
})
.values()
.stream()
.collect(toList());9.3.3. JoinRowMapper
The JoinRowMapper takes a set of types to extract from each row. It uses the mapping registry to determine how to map each given type, and presents you with a JoinRow that holds all the resulting values.
Let’s consider two simple types, User and Article, with a join table named Author. Guava provides a Multimap class, which is very handy for representing joined tables like this. Assuming we have mappers already registered:
h.registerRowMapper(ConstructorMapper.factory(User.class));
h.registerRowMapper(ConstructorMapper.factory(Article.class));we can then easily populate a Multimap with the mapping from the database:
Multimap<User, Article> joined = HashMultimap.create();
h.createQuery("SELECT * FROM \"user\" NATURAL JOIN author NATURAL JOIN article")
.map(JoinRowMapper.forTypes(User.class, Article.class))
.forEach(jr -> joined.put(jr.get(User.class), jr.get(Article.class)));| While this approach is easy to read and write, it can be inefficient for certain patterns of data. Consider performance requirements when deciding whether to use high level mapping or more direct low level access with handwritten mappers. |
You can also use it with SqlObject:
public interface UserArticleDao {
@RegisterJoinRowMapper({User.class, Article.class})
@SqlQuery("SELECT * FROM \"user\" NATURAL JOIN author NATURAL JOIN article")
Stream<JoinRow> getAuthorship();
}Multimap<User, Article> joined = HashMultimap.create();
handle.attach(UserArticleDao.class)
.getAuthorship()
.forEach(jr -> joined.put(jr.get(User.class), jr.get(Article.class)));
assertThat(joined).isEqualTo(JoinRowMapperTest.getExpected());10. Transactions
Jdbi provides full support for JDBC transactions.
10.1. Managed Transactions
A managed transaction is controlled through Jdbi code and provides a handle with an open transaction to user code.
-
The inTransaction and useTransaction methods on the Jdbi object create a new Handle, open a transaction and pass it to the callback code.
-
The inTransaction and useTransaction methods on Handle objects open a transaction on the handle itself and then pass it to the callback code. By default, if these methods are called while the handle is already in an open transaction, the existing transaction is reused (no nested transaction is created).
Each of these methods also has a variant that allows setting the transaction isolation level. Changing the transaction isolation level within an open transaction is not supported (and will cause an exception).
At the end of the callback, the transaction is committed, if
-
the code has not thrown an exception
-
it was not a nested call from another
useTransaction/inTransactioncallback. In that case, control is handed back to the original caller and the transaction finishes when that callback returns. -
the code did not call the rollback() method on the Handle object.
Executing a SQL operation in a transaction:
// use a Jdbi object to create transaction
public Optional<User> findUserById(Jdbi jdbi, long id) {
return jdbi.inTransaction(transactionHandle ->
transactionHandle.createQuery("SELECT * FROM users WHERE id=:id")
.bind("id", id)
.mapTo(User.class)
.findFirst());
}
// use a Handle object to create transaction
public Optional<User> findUserById(Handle handle, long id) {
return handle.inTransaction(transactionHandle ->
transactionHandle.createQuery("SELECT * FROM users WHERE id=:id")
.bind("id", id)
.mapTo(User.class)
.findFirst());
}10.2. Unmanaged Transactions
Jdbi provides the necessary primitives to control transactions directly from a Handle:
-
the begin()/commit()/rollback() methods provide standard transaction semantics
-
setTransactionIsolationLevel() and getTransactionIsolationLevel() to control the transaction isolation level
-
isInTransaction() returns
trueif the handle is currently in a transaction -
savepoint()/releaseSavepoint()/rollbackToSavepoint() for transaction savepoint support. This is not supported by all TransactionHandlers and requires support from the JDBC driver
Transactions are managed by TransactionHandler implementations. By default, transactions are delegated to the JDBC connection and managed through the connection by the database.
The transaction handler can be set per Jdbi instance using the setTransactionHandler and getTransactionHandler methods.
In addition to the standard transaction handler, Jdbi includes a handler that works correctly in a container managed environment and a serializable transaction handler that allows multiple concurrent operations on a single handle to retry transparently.
10.3. Serializable Transactions
For more advanced queries, sometimes serializable transactions are required.
Jdbi includes a transaction runner that is able to retry transactions that abort due to serialization failures.
| It is important that your transaction does not have side effects as it may be executed multiple times. |
// Automatically rerun transactions
jdbi.setTransactionHandler(new SerializableTransactionRunner());
handle.execute("CREATE TABLE ints (value INTEGER)");
// Set up some values
handle.execute("INSERT INTO ints (value) VALUES(?)", 10);
handle.execute("INSERT INTO ints (value) VALUES(?)", 20);
// Run the following twice in parallel, and synchronize
ExecutorService executor = Executors.newCachedThreadPool();
CountDownLatch latch = new CountDownLatch(2);
Callable<Integer> sumAndInsert = () ->
jdbi.inTransaction(TransactionIsolationLevel.SERIALIZABLE, transactionHandle -> {
// Both threads read initial state of table
int sum = transactionHandle.select("SELECT sum(value) FROM ints").mapTo(int.class).one();
// synchronize threads, make sure that they each has successfully read the data
latch.countDown();
latch.await();
// Now do the write.
synchronized (this) {
// handle can be used by multiple threads, but not at the same time
transactionHandle.execute("INSERT INTO ints (value) VALUES(?)", sum);
}
return sum;
});
// Both of these would calculate 10 + 20 = 30, but that violates serialization!
Future<Integer> result1 = executor.submit(sumAndInsert);
Future<Integer> result2 = executor.submit(sumAndInsert);
// One of the transactions gets 30, the other will abort and automatically rerun.
// On the second attempt it will compute 10 + 20 + 30 = 60, seeing the update from its sibling.
// This assertion fails under any isolation level below SERIALIZABLE!
assertThat(result1.get() + result2.get()).isEqualTo(30 + 60);
executor.shutdown();The above test is designed to run two transactions in lock step. Each attempts to read the sum of all rows in the table, and then insert a new row with that sum. We seed the table with the values 10 and 20.
Without serializable isolation, each transaction reads 10 and 20, and then returns 30. The end result is 30 + 30 = 60, which does not correspond to any serial execution of the transactions!
With serializable isolation, one of the two transactions is forced to abort and retry. On the second go around, it calculates 10 + 20 + 30 = 60. Adding to 30 from the other, we get 30 + 60 = 90 and the assertion succeeds.
11. Configuration
Jdbi aims to be useful out of the box with minimal configuration. If necessary, there is a wide range of configurations and customizations available to change the default behavior or add in extensions to handle additional database types.
Configuration is managed by the ConfigRegistry class. Each Jdbi object that represents a distinct database context (for example, Jdbi itself, a Handle instance, or an attached SqlObject class) has a separate config registry instance.
When a new context is created, it inherits a copy of its parent configuration at the time of creation - further modifications to the original will not affect already created configuration contexts. Configuration context copies happen when creating a Handle from Jdbi, when opening a SqlStatement from the Handle, and when attaching or creating an on-demand extension such as SqlObject.
A configurable Jdbi object implements the Configurable interface which allows modification of its configuration as well as retrieving the current context’s configuration for use by Jdbi core or extensions.
// fetch the config registry object
ConfigRegistry config = jdbi.getConfig();
// access the SqlStatements configuration object:
SqlStatements sqlStatements = jdbi.getConfig(SqlStatements.class);
// modify a setting in SqlStatements with a callback
jdbi.configure(SqlStatements.class, s -> s.setUnusedBindingAllowed(true));
// modify a setting in SqlStatements with direct method invocation
jdbi.getConfig(SqlStatements.class).setUnusedBindingAllowed(true);The Configurable interface also adds a number of convenience methods for commonly used configuration objects.
See JdbiConfig for more advanced implementation details.
11.1. core settings
| Object | Property | Type | Default | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
bindingNullToPrimitivesPermitted |
boolean |
|
Allows binding |
|||||||||||||||
preparedArgumentsEnabled |
boolean |
|
PreparedArguments speed up argument processing but have some backwards compatibility risk with old (pre-3.24.0) releases. |
|||||||||||||||
untypedNullArgument |
NullArgument using Types.OTHER. |
This argument instance is invoked when a |
||||||||||||||||
coalesceNullPrimitivesToDefaults |
boolean |
|
Uses the driver default value for primitive types if a SQL NULL value was returned by the database. The exact value used is specific to the database driver. |
|||||||||||||||
enumStrategy |
|
Sets the strategy to map a Java enum value onto a database column. Available strategies are
|
||||||||||||||||
allowProxy |
boolean |
|
Whether Jdbi is allowed to create proxy instances for classes (as extension and on-demand reference). This is useful for debugging when using the generator to create java classes for sql objects. |
|||||||||||||||
failFast |
boolean |
|
If set to |
|||||||||||||||
forceEndTransactions |
boolean |
|
Whether to ensure transaction discipline. If |
|||||||||||||||
caseChange |
Defines the strategy for mapping the database column names to key names. Available strategies are:
Custom strategies can be set by implementing UnaryOperator<String> with custom code. |
|||||||||||||||||
caseChange |
Defines the strategy for mapping the database column names to key names. Available strategies are:
Custom strategies can be set by implementing UnaryOperator<String> with custom code. |
|||||||||||||||||
strictMatching |
boolean |
|
If |
|||||||||||||||
allowNoResults |
boolean |
|
If |
|||||||||||||||
maxRetries |
int |
|
number of times a transaction is retried if the database reports a serialization error. |
|||||||||||||||
onFailure |
<unset> |
Is called whenever a serialization failure occurs. Can be used e.g. for logging. |
||||||||||||||||
onSuccess |
<unset> |
Is called once a transaction successfully finishes with any exception that has happened during the transaction execution. |
||||||||||||||||
serializationFailureSqlState |
String |
|
SQL state value from a |
|||||||||||||||
argumentStrategy |
Sets the strategy on how to bind arrays in the database driver.
|
|||||||||||||||||
attachAllStatementsForCleanup |
boolean |
|
Jdbi supports automatic resource management by attaching statements to their handle so that closing the handle will free up all its resources.
If this setting is |
|||||||||||||||
attachCallbackStatementsForCleanup |
boolean |
|
Similar to |
|||||||||||||||
queryTimeout |
Integer |
<unset> |
Sets the query timeout value in seconds. This value is used to call Statement#setQueryTimeout. Enforcement of the timeout depends on the JDBC driver. |
|||||||||||||||
sqlParser |
The parser used to find the placeholders to bind arguments to. Jdbi currently provides the following parsers:
Custom implementations must implement SqlParser and may extend CachingSqlParser to benefit from caching. |
|||||||||||||||||
sqlLogger |
<unset> |
Controls logging around statement execution. A SqlLogger instance receives the statement context before and after query execution and the context and an exception in case of an execution problem. Jdbi provides Slf4JSqlLogger for the popular slf4j logging framework. |
||||||||||||||||
templateEngine |
The template engine to render SQL statements and substitute placeholders with values that have been defined on a statement (This is for defined attributes, not bound attributes!).
Custom implementations must implement TemplateEngine. |
|||||||||||||||||
unusedBindingsAllowed |
boolean |
|
All bindings to a SQL operation must be used or an exception is thrown. If this setting is |
|||||||||||||||
lengthLimit |
int |
|
Controls the maximum length for variable length strings when they are rendered using the |
|||||||||||||||
messageRendering |
Sets the message rendering strategy when fetching the message from a StatementException and its subclasses. Controls how error messages from a Statement are displayed (e.g. for logging).
|
11.2. SQLObject configuration settings
| Object | Property | Type | Default | Description | ||||
|---|---|---|---|---|---|---|---|---|
sqlLocator |
Sets the locator for finding SQL statements. Default is to look for SQL operation annotations. Jdbi provides two implementations of the
|
|||||||
timezone |
system zone id |
Sets the timezone for the @Timestamped annotation. |
11.3. other configuration settings
| Object | Property | Type | Default | Description |
|---|---|---|---|---|
jsonMapper |
see description |
Sets the JSON implementation used to serialize and deserialize json columns. Needs to be set when using the generic Json serialization/deserialization mapper. When installing the If none of these modules is loaded, it defaults to an implementation that throws an exception whenever serialization or deserialization is attempted. |
||
gson |
A |
Sets the Gson object used to parse and render json text. |
||
mapper |
An |
Sets the object mapper instance used to parse and render json text. |
||
deserializationView |
<unset> |
Sets a view (see @JsonView) for deserialization. Can be used to limit the values read when mapping a json column. |
||
serializationView |
<unset> |
Sets a view (see @JsonView) for serialization. Can be used to limit the values written when using a json argument. |
||
view |
<unset> |
Sets a view (see @JsonView) for serialization and deserialization. Can be used to limit the values read and written by json arguments and mappers. |
||
moshi |
A |
Sets the Moshi instance used to parse and render json text. |
||
freemarkerConfiguration |
The default configuration object. |
Sets the freemarker configuration object for the template engine. See the freemarker documentation for details. The default configuration has the following modifications for Jdbi:
|
||
failOnMissingAttribute |
boolean |
|
If |
12. SQL Arrays
Jdbi can bind/map Java arrays to/from SQL arrays:
handle.createUpdate("INSERT INTO groups (id, user_ids) VALUES (:id, :userIds)")
.bind("id", 1)
.bind("userIds", new int[] {10, 5, 70})
.execute();
int[] userIds = handle.createQuery("SELECT user_ids FROM groups WHERE id = :id")
.bind("id", 1)
.mapTo(int[].class)
.one();You can also use Collections in place of arrays, but you’ll need to provide the element type if you’re using the fluent API, since it’s erased:
handle.createUpdate("INSERT INTO groups (id, user_ids) VALUES (:id, :userIds)")
.bind("id", 1)
.bindArray("userIds", int.class, Arrays.asList(10, 5, 70))
.execute();
List<Integer> userIds = handle.createQuery("SELECT user_ids FROM groups WHERE id = :id")
.bind("id", 1)
.mapTo(new GenericType<List<Integer>>() {})
.one();Use @SingleValue for mapping an array result with the SqlObject API:
public interface GroupsDao {
@SqlQuery("SELECT user_ids FROM groups WHERE id = ?")
@SingleValue
List<Integer> getUserIds(int groupId);
}12.1. Registering array types
Any Java array element type you want binding support for needs to be registered
with Jdbi’s SqlArrayTypes registry. An array type that is directly supported
by your JDBC driver can be registered using:
jdbi.registerArrayType(int.class, "integer");Here, "integer" is the SQL type name that the JDBC driver supports natively.
Plugins like PostgresPlugin and H2DatabasePlugin automatically
register the most common array element types for their respective databases.
|
Postgres supports enum array types, so you can register an array type for
enum Colors { red, blue } using jdbi.registerArrayType(Colors.class, "colors")
where "colors" is a user-defined enum type name in your database.
|
12.2. Binding custom array types
You can also provide your own implementation of SqlArrayType that converts
a custom Java element type to a type supported by the JDBC driver:
class UserArrayType implements SqlArrayType<User> {
@Override
public String getTypeName() {
return "integer";
}
@Override
public Object convertArrayElement(User user) {
return user.getId();
}
}You can now bind instances of User[] to arguments of data type integer[]:
User user1 = new User(1, "bob");
User user2 = new User(42, "alice");
handle.registerArrayType(new UserArrayType());
handle.createUpdate("INSERT INTO groups (id, user_ids) VALUES (:id, :users)")
.bind("id", 1)
.bind("users", new User[] {user1, user2})
.execute();
Like the Arguments Registry, if there are multiple SqlArrayType s
registered for the same data type, the last registered wins.
|
12.3. Mapping array types
SqlArrayType only allows you to bind Java array/collection arguments to their
SQL counterparts. To map SQL array columns back to Java types, you can register
a regular ColumnMapper:
public class UserIdColumnMapper implements ColumnMapper<UserId> {
@Override
public UserId map(ResultSet rs, int col, StatementContext ctx) throws SQLException {
return new UserId(rs.getInt(col));
}
}handle.registerColumnMapper(new UserIdColumnMapper());
List<UserId> userIds = handle.createQuery("SELECT user_ids FROM groups WHERE id = :id")
.bind("id", 1)
.mapTo(new GenericType<List<UserId>>() {})
.one();
Array columns can be mapped to any container type registered with the
JdbiCollectors registry. E.g. a VARCHAR[] may be mapped to an
ImmutableList<String> if the Guava plugin is installed.
|
13. SQL Objects
SQL Objects are a declarative-style extension to the fluent-style, programmatic Core APIs. SQL Objects are implemented as an extension to the core API using the Extension framework.
To start using the SQL Object plugin, add a dependency to your project:
For Apache Maven:
<dependencies>
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-sqlobject</artifactId>
<version>3.41.2</version>
</dependency>
</dependencies>For Gradle:
dependencies {
implementation("org.jdbi:jdbi3-sqlobject:3.41.2")
}Then install the plugin into the Jdbi instance:
Jdbi jdbi = ...
jdbi.installPlugin(new SqlObjectPlugin());With SQL Object, you declare a public interface class as a SQL Object extension type, add methods for database operations, and specify what SQL statement to execute.
You can specify what each method does in one of two ways:
-
Annotate the method with a SQL method annotation. Jdbi provides a number of these annotations out of the box.
-
Use Java interface default methods, and provide your own implementation in the method body.
At runtime, you can request an instance of your interface, and Jdbi synthesizes an implementation based on the annotations and methods you declared.
13.1. SQL Method annotations
Interface methods can be annotated with one of Jdbi’s SQL method annotations:
-
@SqlQuery - select operations that return data
-
@SqlUpdate - insert, update, delete etc. operations that modify data
-
@SqlBatch - bulk operations
-
@SqlCall - call stored procedures
-
@SqlScript - execute multiple statements as a script
As with any extension type, parameters to the method are used as arguments. For the SQL Object extension, the arguments are passed to the statement, and the SQL statement result is mapped to the method return type.
SQL Object provides data mapping onto return types, argument mapping and mapper annotations to allow fully declarative definition of SQL queries.
13.1.1. @SqlQuery
Use the @SqlQuery annotation for select operations. Each operation may return one or more rows which are mapped onto a return type by the SQL Object extension.
This is an example for a simple query:
@SqlQuery("SELECT id, name FROM users") (1)
List<User> retrieveUsers(); (2)| 1 | defines the SQL query that gets executed |
| 2 | The method can return any type. The SQL Object framework will map the response from the SQL query onto this data type. |
The SQL Object plugin uses the same configuration as the Jdbi core framework. Row and column mappers need to be registered to map to the correct types. This can be done through configuration or by using Mapper annotations.
13.1.2. @SqlUpdate
Use the @SqlUpdate annotation for operations that modify data (i.e. inserts, updates, deletes).
This is an example that uses PreparedStatement placeholders (?) for arguments:
public interface UserDao {
@SqlUpdate("INSERT INTO users (id, name) VALUES (?, ?)") (1)
void insert(long id, String name); (2)
}| 1 | Method arguments are bound to the ? token in the SQL statement at their respective positions. |
| 2 | id is bound to the first placeholder (?), and name to the second placeholder. |
| @SqlUpdate can also be used for DDL (Data Definition Language) operations like creating or altering tables. However, we recommend using a schema migration tool such as Flyway or Liquibase to maintain your database schemas. |
By default, a @SqlUpdate method may declare one of these return types:
-
void- no return value -
intorlong- returns the update count. Depending on the database vendor and JDBC driver, this may be either the number of rows changed, or the number matched by the query (regardless of whether any data was changed). -
boolean- returns true if the update count is greater than zero.
Some databases also support returning additional values. See the @GetGeneratedKeys annotation for more details.
13.1.3. @SqlBatch
Use the @SqlBatch annotation for bulk update operations. It works similar to the PreparedBatch operation in the Jdbi core.
public interface ContactDao {
@SqlBatch("INSERT INTO contacts (id, name, email) VALUES (?, ?, ?)")
void bulkInsert(List<Integer> ids, (1)
Iterator<String> names, (2)
String... emails); (3)
}| 1 | a collection argument for the batch operation |
| 2 | an iterable argument for the batch operation |
| 3 | a varargs argument for the batch operation |
When a batch method is called, it iterates through the method’s iterable parameters (collections, iterables, varargs etc.), and executes the SQL statement with the corresponding elements from each parameter.
Thus, a statement like:
contactDao.bulkInsert(
ImmutableList.of(1, 2, 3),
ImmutableList.of("foo", "bar", "baz").iterator(),
"a@example.com", "b@example.com", "c@fake.com");would execute:
INSERT INTO contacts (id, name, email) VALUES (1, 'foo', 'a@example.com');
INSERT INTO contacts (id, name, email) VALUES (2, 'bar', 'b@example.com');
INSERT INTO contacts (id, name, email) VALUES (3, 'baz', 'c@fake.com');Constant values may also be used as parameters to a SQL batch. In this case, the same value is bound to that parameter for every SQL statement in the batch.
public interface UserDao {
@SqlBatch("INSERT INTO users (tenant_id, id, name) " +
"VALUES (:tenantId, :user.id, :user.name)")
void bulkInsert(@Bind("tenantId") long tenantId, (1)
@BindBean("user") User... users);
}| 1 | Insert each user record using the same tenant_id. See SQL Object arguments mapping for details about the @Bind annotation. |
| Any method annotated with @SqlBatch must have at least one iterable parameter. |
By default, methods annotated with @SqlBatch may declare one of these return types:
-
void- no return value -
int[]orlong[]- returns the update count per execution in the batch. Depending on the database vendor and JDBC driver, this may be either the number of rows changed by a statement, or the number matched by the query (regardless of whether any data was changed). -
boolean[]- returns true if the update count is greater than zero, one value for each execution in the batch.
13.1.4. @SqlCall
Use the @SqlCall annotation to call stored procedures.
public interface AccountDao {
@SqlCall("{call suspend_account(:id)}")
void suspendAccount(long id);
}@SqlCall methods can return void, or may return
OutParameters if the stored procedure has any output parameters. Each output parameter must be registered
with the @OutParameter annotation.
public interface OrderDao {
@SqlCall("{call prepare_order_from_cart(:cartId, :orderId, :orderTotal)}")
@OutParameter(name = "orderId", sqlType = java.sql.Types.BIGINT)
@OutParameter(name = "orderTotal", sqlType = java.sql.Types.DECIMAL)
OutParameters prepareOrderFromCart(@Bind("cartId") long cartId);
}Individual output parameters can be extracted from the OutParameters returned from the method:
OutParameters outParams = orderDao.prepareOrderFromCart(cartId);
long orderId = outParams.getLong("orderId");
double orderTotal = outParams.getDouble("orderTotal");@SqlCall supports special arguments for OutParameters processing.
13.1.5. @SqlScript
Use @SqlScript to execute one or more statements in a batch.
While @SqlBatch executes the same SQL statement with different values, the @SqlScript annotation executes different SQL statements without explicit data bound to each statement.
@SqlScript("CREATE TABLE <name> (pk int primary key)") (1)
void createTable(@Define String name); (2)
@SqlScript("INSERT INTO cool_table VALUES (5), (6), (7)")
@SqlScript("DELETE FROM cool_table WHERE pk > 5")
int[] doSomeUpdates(); // returns [ 3, 2 ]
@UseClasspathSqlLocator (3)
@SqlScript (4)
@SqlScript("secondScript") (5)
int[] externalScript();| 1 | Sql scripts can use substitute placeholders. The default template engine uses angle brackets (< and >). |
| 2 | The @Define annotation provides values for the placeholder attributes |
| 3 | The @UseClasspathSqlLocator annotation loads SQL templates from the classpath |
| 4 | Use the name of the annotated method to locate the script |
| 5 | specify the script name in the annotation |
By default, methods annotated with @SqlScript may declare one of these return types:
-
void- no return value -
int[]orlong[]- return value of each statement executed. Depending on the database vendor and JDBC driver, this may be either the number of rowsreturn nothing changed by a statement, or the number matched by the query (regardless of whether any data was changed). -
boolean[]- returns true if the update count is greater than zero, one value for each statement in the script.
13.2. Using SQL Objects
SQL Object types are regular Java interfaces classes that must be public. Once they have been defined, there are multiple ways to use them. They differ in the lifecycle of the underlying Handle object:
-
attached to an existing handle object
The Handle#attach() method uses an existing handle to create a SQL object instance:
try (Handle handle = jdbi.open()) {
ContactPhoneDao dao = handle.attach(ContactPhoneDao.class);
dao.insertFullContact(contact);
}Attached SQL Objects have the same lifecycle as the handle—when the handle is closed, the SQL Object becomes unusable.
-
using Jdbi extension methods
SQL Object types can be created using Jdbi#withExtension() for operations that return a result, or Jdbi#useExtension() for operations with no result. These methods take a callback (or a lambda object) and provide it with a managed instance of the SQL object type:
jdbi.useExtension(ContactPhoneDao.class, dao -> dao.insertFullContact(alice));
long bobId = jdbi.withExtension(ContactPhoneDao.class, dao -> dao.insertFullContact(bob));-
creating an on-demand object
On-demand instances are constructed with the Jdbi#onDemand() method. They have an open-ended lifecycle, as they obtain and release a connection for each method call. They are thread-safe, and may be reused across an application.
ContactPhoneDao dao = jdbi.onDemand(ContactPhoneDao.class);
long aliceId = dao.insertFullContact(alice); (1)
long bobId = dao.insertFullContact(bob); (1)| 1 | each of these operations creates and releases a new database connection. |
The performance of on-demand objects depends on the database and database connection pooling. For performance critical operations, it may be better to manage the handle manually and use attached objects.
13.2.1. Interface default methods
Interface default methods on a SQL object type can provide custom code functionality that uses the same handle as the SQL Object methods.
The SQL object framework manages the underlying handle so that calling a method on the same object on the same thread will use the same Handle object. If the handle is managed by the framework, it will only be closed when the outermost method exits.
@Test
void testDefaultMethod() {
UserDao dao = jdbi.onDemand(UserDao.class);
assertThat(dao.findUser(1))
.isPresent()
.contains(new User(1, "Alice"));
dao.changeName(1, "Alex"); (1)
assertThat(dao.findUser(1))
.isPresent()
.contains(new User(1, "Alex"));
}
interface UserDao {
@SqlQuery("SELECT * FROM users WHERE id = :id")
Optional<User> findUser(int id);
@SqlUpdate("UPDATE users SET name = :name WHERE id = :user.id")
void updateUser(@BindMethods("user") User user, String name);
default void changeName(int id, String name) {
findUser(id).ifPresent(user -> updateUser(user, name)); (2)
}
}| 1 | The changeName() method is called by the user code |
| 2 | The implementation will call both findUser() and updateUser() with the same handle object. |
13.3. SQL Object method arguments
All SQL Object methods support method arguments. Method arguments are mapped onto SQL statement parameters.
13.3.1. Mapping arguments to positional parameters
By default, arguments passed to the method are bound as positional parameters in the SQL statement:
public interface UserDao {
@SqlUpdate("INSERT INTO users (id, name) VALUES (?, ?)") (1)
void insert(long id, String name); (2)
}| 1 | declares two positional parameters |
| 2 | provides two method parameters. id will be bound as the first, name as the second parameter. |
This matches the PreparedStatement way of binding arguments to a statement. Jdbi binds the arguments as the correct types and convert them if necessary.
13.3.2. Mapping arguments to named parameters
The Jdbi core supports named parameters in SQL statements. When using the SQL Object extension, those can be bound to specific method arguments using annotations.
The @Bind annotation binds a single method argument to a named parameter:
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)") (1)
void insert(@Bind("name") String name, @Bind("id") long id); (2)| 1 | The SQL statement uses two named parameters, :id and :name |
| 2 | The method declaration annotates each parameter with the @Bind annotation with matching names. The order is not important as each method parameter is explicitly named |
Similar to the methods on the Handle, arguments can be bound in many different ways:
Bind any iterable object with @BindList
Any Java object that implements the Iterable interface can be bound using the @BindList annotation. This will iterate the elements in 'a,b,c,d,…' form.
This annotation requires you to use a template placeholder (using the <field> notation when using the default template engine), similar to the SqlStatement#bindList() method. Templates placeholders are incompatible with batch operations such as`PreparedBatch` as they are evaluated only once and the evaluated statement is cached. If subsequent batch executions use an iterable object with a different size, the number of placeholders and arguments will not match. If the database supports array types, it is strongly recommended to use bindArray() with a SQL array instead of the bindList() method.
|
@SqlQuery("SELECT name FROM users WHERE id in (<userIds>)")
List<String> getFromIds(@BindList("userIds") List<Long> userIds)Bind map instances with @BindMap
Entries from a Map can be bound using the @BindMap annotation. Each entry from the map is bound as a named parameter using the map key as the name and the map value as the value. Jdbi will bind the values as the correct types and convert them if necessary:
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)") (1)
void insert(@BindMap Map<String, ?> map); (2)| 1 | The SQL statement expects two named parameters, :id and :name |
| 2 | Jdbi will look for two keys, id and a name in the map. The values for these keys are bound to the parameters. |
Bind bean getters with @BindBean
Java Bean getters can be bound with the @BindBean annotation:
class UserBean {
private int id;
private String name;
public UserBean() {}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
}
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insertUserBean(@BindBean UserBean user);This annotation uses the Java Bean syntax for getters.
Bind parameterless public methods with @BindMethods
Similar to @BindBean, the @BindMethods annotation bean methods as parameters. For each binding, it looks for a method with the same name:
class User {
private final int id;
private final String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int id() {
return id;
}
public String name() {
return name;
}
}
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insertUser(@BindMethods User user);| When using Java 14+ record types, all getters from the record can be bound using the @BindMethods annotation. |
Bind public fields from a java object with @BindFields
Many objects offer public fields instead of getters. Those can be bound by using the @BindFields annotation:
class UserField {
public int id;
public String name;
}
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insertUserField(@BindFields UserField user);Using object prefixes
The `@BindMap, @BindBean, @BindMethods, and @BindFields annotations support an optional prefix:
@SqlUpdate("INSERT INTO users (id, name) VALUES (:user.id, :user.name)")
(1)
void insertUserBeanPrefix(@BindBean("user") UserBean user); (2)| 1 | The id and name parameters are prefixed with user. |
| 2 | The User object which provides the values uses a prefix. The user.id parameter will be mapped to the getId() method of this bean and the user.name parameter to the getName() method. |
By providing prefixes, it is possible to use multiple objects with different prefixes or mix map and regular bound parameters.
@SqlUpdate("INSERT INTO users (id, name, password) VALUES (:user.id, :user.name, :password)")
void insert(@BindMap("user") Map<String, ?> map, @Bind("password") String password);Even if the provided map would contain a key named password, it would not be used, because all values from the map are bound with the user prefix.
Using nested properties
Similar to the Core API, the @BindBean, @BindFields, and @BindMethods annotation will also map nested properties.
A Java object that returns a nested object can be bound and then nested properties are addressed using e.g. :user.address.street.
This functionality is not available for Map objects that have been bound with @BindMap. Map keys must match the bound parameter name.
class NestedUser {
private final User user;
private final String tag;
public NestedUser(User user, String tag) {
this.user = user;
this.tag = tag;
}
public User user() {
return user;
}
public String tag() {
return tag;
}
}
@SqlUpdate("INSERT INTO users (id, name) VALUES (:user.id, :user.name)")
void insertUser(@BindMethods NestedUser user);| "Mixes style" nested properties are not supported. Any nested object will be inspected in the same way as the root object. All nested objects must use either bean-style, methods or fields. |
13.3.3. Mapping arguments to Java parameter names
When compiling a project with parameter names enabled, the @Bind annotation is not needed. SQLObjects will bind un-annotated parameters to their names.
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insert(long id, String name);13.3.4. Consumer arguments
In addition to the regular method arguments for a SQL Object method, it is possible to use a single Consumer<T> argument in addition to other arguments.
Consumer arguments are actually a special return type for SQL operations. They can be used to consume the results from a SQL operation with a callback instead of returning a value from the method.
Any SQL operation method that wants to use a consumer argument must return void. It can declare only a single consumer argument, but can have additional regular method arguments. The consumer argument can be in any position in the argument list. .
Unless the type T is a Stream, Iterator or Iterable, the consumer is executed once for each row in the result set. The static type of parameter T determines the row type.
@SqlQuery("SELECT * FROM users WHERE id = :id")
@RegisterConstructorMapper(User.class)
void consumeUser(int id, Consumer<User> consumer); (1)
@SqlQuery("SELECT * FROM users")
@RegisterConstructorMapper(User.class)
void consumeMultiUsers(Consumer<User> consumer); (2)| 1 | This SQL operation may return no or just one result. The consumer argument will only be invoked if a user exists. |
| 2 | This SQL operation may return multiple results. It will invoke the consumer argument once for every result. |
If the consumer implements Stream, Iterator or Iterable, then the consumer is executed once with the corresponding object holding the results. The static type of parameter T determines the mapped row type here as well. If the result set is empty, the SQL Object framework may not call the consumer or may call it with an empty result object.
@SqlQuery("SELECT * FROM users")
@RegisterConstructorMapper(User.class)
void consumeMultiUserIterable(Consumer<Iterable<User>> consumer); (1)| 1 | This consumer argument is called once if any number of results are present. It may be called with an empty iterable object or not at all if no results are present. |
| When using Consumer<Iterable> as a consumer argument, the Iterable object passed into the consumer is NOT a general-purpose Iterable as it supports only a single invocation of the Iterable#iterator() method. Invoking it the iterator method again to obtain a second or subsequent iterator may throw IllegalStateException. |
@SqlCall Consumer and Function arguments
The @SqlCall annotation supports either a Consumer argument or a Function argument for the OutParameters return value.
A method that has been annotated with @SqlCall may have any number of regular method arguments and
-
declare
voidor OutParameters as its return type. -
declare
voidas its return type and have a single Consumer<OutParameters> consumer argument -
declare an arbitrary type
Tas return type and have a single Function<OutParameters, T> function argument
When using a consumer or function argument, these are called to process the OutParameters value before the statement is closed.
13.3.5. Mapping arguments to defined attributes
The Jdbi core framework supports attributes that can be used anywhere in the SQL statement or that can control Query template rendering. The @Define annotation provides this functionality for the SQL Object extension:
interface UserDao {
@SqlQuery("SELECT name FROM <table>") (1)
List<String> getNames(@Define("table") String tableName); (2)
}
@Test
void testNames() {
List<String> result = jdbi.withExtension(UserDao.class, dao -> dao.getNames("users")); (3)
assertThat(result).containsAll(names);
}| 1 | declare an attribute placeholder for the table name |
| 2 | bind the placeholder to the method argument |
| 3 | provide the value for the placeholder when calling the SQL object method |
13.4. SQL Object method return values
The SQL Object framework will try to convert the result of a database operation to the declared return value of a SQL Object method.
This is most important for @SqlQuery operations as most other operations have a very limited set of possible return values:
-
@SqlUpdate - supports
void,int,long,boolean -
@SqlBatch - supports
void,int[],long[],boolean[] -
@SqlScript - supports
void,int[],long[],boolean[] -
@SqlCall - supports
void, OutParameters (and function arguments)
Query methods may return a single row or multiple rows, depending on whether the method return type looks like a collection:
public interface UserDao {
@SqlQuery("SELECT name FROM users")
List<String> listNames(); (1)
@SqlQuery("SELECT name FROM users WHERE id = ?")
String getName(long id); (2)
@SqlQuery("SELECT name FROM users WHERE id = ?")
Optional<String> findName(long id); (3)
@SqlQuery("SELECT id, name FROM users WHERE id = ?")
Optional<User> findUser(long id); (4)
}| 1 | Returns a collection of results. This is never null, an empty collection is returned for an empty result set. |
| 2 | Returns a single result. If the query returns a result set with multiple rows, then only the first row is returned. If the row set is empty, null is returned. |
| 3 | Methods may return Optional values. If the query returns no rows (or if the value in the row is null),
Optional.empty() is returned instead of null. SQL Object throws an exception if query returns more than one
row. |
| 4 | When returning a complex type, Jdbi must have row and column mappers registered, otherwise it will throw an exception. These can be registered through the Jdbi core API or with annotations. |
| Jdbi can use different collection types by registering a CollectorFactory with the JdbiCollectors config registry. |
See BuiltInCollectorFactory for the complete list of collection types supported out of the box. Some Jdbi plugins (e.g. the GuavaPlugin) register additional collection types.
13.4.1. Using Streams and Iterators
SQL Object method may return ResultIterable, ResultIterator or Stream types. Each of these return values represents a cursor-type object that requires an active Handle object with a database connection to support streaming results.
All SQL object type methods are subject to the extension framework Handle lifecycle. When the Handle object is closed, the database connection and the corresponding stream or iterator is closed as well.
This is an example of a SQL Object type that returns cursor types:
interface UserDao {
@SqlQuery("SELECT name FROM users")
Stream<String> getNamesAsStream();
@SqlQuery("SELECT name FROM users")
ResultIterable<String> getNamesAsIterable();
@SqlQuery("SELECT name FROM users")
ResultIterator<String> getNamesAsIterator();
}Use the method return value directly
Only the Handle#attach() method allows cursor type objects as SQL Object method return values. Calling this method attaches the object to the Handle lifecycle which in turn is managed by user code:
@Test
void testHandleAttach() {
try (Handle handle = jdbi.open()) { (1)
UserDao dao = handle.attach(UserDao.class);
try (Stream<String> stream = dao.getNamesAsStream()) { (2)
List<String> result = stream.collect(Collectors.toList()); (3)
assertThat(result).containsAll(names);
}
}
}| 1 | The handle is managed in user code. |
| 2 | The stream is also managed. |
| 3 | The returned stream is used within the try-with-resources block. |
The objects returned from these methods hold database resources that should be closed. Jdbi usually handles resources well but using a try-with-resource block is a good practice:
try (ResultIterable<String> names = dao.getNamesAsIterable()) {
// ...
}
try (ResultIterator<String> names = dao.getNamesAsIterator()) {
// ...
}
try (Stream<String> names = dao.getNamesAsStream()) {
// ...
}The Jdbi#withExtension() or Jdbi#useExtension() methods can not be used:
@Test
void testWithExtensionFails() {
assertThatThrownBy(() -> {
List<String> result = jdbi.withExtension(UserDao.class, UserDao::getNamesAsStream).collect(Collectors.toList()); (1)
assertThat(result).containsAll(names);
}).isInstanceOf(ResultSetException.class); (2)
}| 1 | The handle is closed when leaving the Jdbi#withExtension() method. |
| 2 | Calling the Stream#collect() method on the returned stream causes a ResultSetException. |
The Jdbi#onDemand() method can not be used either:
@Test
void testOnDemandFails() {
assertThatThrownBy(() -> {
UserDao dao = jdbi.onDemand(UserDao.class);
List<String> result = dao.getNamesAsStream().collect(Collectors.toList()); (1)
assertThat(result).containsAll(names);
}).isInstanceOf(ResultSetException.class); (2)
}| 1 | The handle is closed when leaving the getNamesAsStream method. |
| 2 | Calling the Stream#collect() method on the returned stream causes a ResultSetException. |
Use interface default methods
The SQL Object framework closes the Handle object when returning from the outermost method in a SQL object type. It is possible to write processing logic in an interface default method:
interface UserDao {
@SqlQuery("SELECT name FROM users")
Stream<String> getNamesAsStream();
default List<String> getNames() { (1)
try (Stream<String> stream = getNamesAsStream()) { (2)
return stream.collect(Collectors.toList()); (3)
}
}
}| 1 | The handle is closed when exiting the getNames method as this is the outermost method in the UserDao object. |
| 2 | The stream is managed with a try-with-resources block. |
| 3 | The stream can be processed within the getNames method. |
The default method can be used with the Jdbi#onDemand(), Jdbi#withExtension() and Jdbi#useExtension() methods:
@Test
void testOnDemandDefaultMethod() {
UserDao dao = jdbi.onDemand(UserDao.class);
List<String> result = dao.getNames();
assertThat(result).containsAll(names);
}
@Test
void testWithExtensionDefaultMethod() {
List<String> result = jdbi.withExtension(UserDao.class, UserDao::getNames);
assertThat(result).containsAll(names);
}Use consumer arguments
Using the method return value either directly or through an interface default method has the drawback that the user code to process the cursor-type object must be written within the SQL Object type as it must be executed before closing the Handle object.
An elegant way to sidestep this problem is using a consumer argument to provide a callback:
interface CallbackDao {
@SqlQuery("SELECT name FROM users")
void getNamesAsStream(Consumer<Stream<String>> consumer);
}@Test
void testHandleAttachCallback() {
try (Handle handle = jdbi.open()) { (1)
CallbackDao dao = handle.attach(CallbackDao.class);
List<String> result = new ArrayList<>();
dao.getNamesAsStream(stream -> stream.forEach(result::add)); (2)
assertThat(result).containsAll(names);
}
}| 1 | The Handle lifecycle must still be managed by user code. |
| 2 | The stream is managed by the SQL object framework and does not need to be closed by user code. |
This code also works with the Jdbi#onDemand() and Jdbi#useExtension() methods:
@Test
void testOnDemandCallback() {
CallbackDao dao = jdbi.onDemand(CallbackDao.class);
List<String> result = new ArrayList<>();
dao.getNamesAsStream(stream -> stream.forEach(result::add));
assertThat(result).containsAll(names);
}
@Test
void testWithExtensionCallback() {
List<String> result = new ArrayList<>();
jdbi.useExtension(CallbackDao.class, dao -> (1)
dao.getNamesAsStream(stream -> stream.forEach(result::add)));
assertThat(result).containsAll(names);
}| 1 | This code uses Jdbi#useExtension() instead of Jdbi#withExtension() as the SQL Object method returns void. |
| While using a consumer argument is a great way to deal with cursor-type objects, there is the drawback that the user code is called while holding the handle (or the database connection) open. If the callback does very expensive or slow processing, this may hold the connection for a very long time. |
13.5. SQL Object mapper annotations
The most common use for annotations is to register specific row and column mappers to return values from @SqlQuery.
13.5.1. @RegisterRowMapper
Use @RegisterRowMapper to register a concrete row mapper class:
public interface UserDao {
@SqlQuery("SELECT * FROM users")
@RegisterRowMapper(UserMapper.class)
List<User> list();
}Row mappers used with this annotation must meet a few requirements:
public class UserMapper implements RowMapper<User> { (1) (2)
public UserMapper() { (3)
// ...
}
public T map(ResultSet rs, StatementContext ctx) throws SQLException {
// ...
}
}| 1 | Must be a public class. |
| 2 | Must implement RowMapper with an explicit type argument (e.g. RowMapper<User>) instead of a type variable (e.g. RowMapper<T>). |
| 3 | Must have a public, no-argument constructor (or a default constructor). |
| The @RegisterRowMapper annotation may be repeated multiple times on the same type or method to register multiple mappers. |
13.5.2. @RegisterRowMapperFactory
Use @RegisterRowMapperFactory to register a RowMapperFactory.
public interface UserDao {
@SqlQuery("SELECT * FROM users")
@RegisterRowMapperFactory(UserMapperFactory.class)
List<User> list();
}Row mapper factories used with this annotation must meet a few requirements:
public class UserMapperFactory implements RowMapperFactory { (1)
public UserMapperFactory() { (2)
// ...
}
public Optional<RowMapper<?>> build(Type type, ConfigRegistry config) {
// ...
}
}| 1 | Must be a public class. |
| 2 | Must have a public, no-argument constructor (or a default constructor). |
| The @RegisterRowMapperFactory annotation may be repeated multiple times on the same type or method to register multiple factories. |
13.5.3. @RegisterColumnMapper
Use @RegisterColumnMapper to register a column mapper:
public interface AccountDao {
@SqlQuery("SELECT balance FROM accounts WHERE id = ?")
@RegisterColumnMapper(MoneyMapper.class)
Money getBalance(long id);
}Column mappers used with this annotation must meet a few requirements:
public class MoneyMapper implements ColumnMapper<Money> { (1) (2)
public MoneyMapper() { (3)
// ...
}
public T map(ResultSet r, int columnNumber, StatementContext ctx) throws SQLException {
// ...
}
}| 1 | Must be a public class. |
| 2 | Must implement ColumnMapper with an explicit type argument (e.g. ColumnMapper<User>) instead of a type variable (e.g. ColumnMapper<T>). |
| 3 | Must have a public, no-argument constructor (or a default constructor). |
| The @RegisterColumnMapper annotation may be repeated multiple times on the same type or method to register multiple mappers. |
13.5.4. @RegisterColumnMapperFactory
Use @RegisterColumnMapperFactory to register a column mapper factory:
public interface AccountDao {
@SqlQuery("SELECT * FROM users")
@RegisterColumnMapperFactory(MoneyMapperFactory.class)
List<User> list();
}Column mapper factories used with this annotation must meet a few requirements:
public class UserMapperFactory implements RowMapperFactory { (1)
public UserMapperFactory() { (2)
// ...
}
public Optional<RowMapper<?>> build(Type type, ConfigRegistry config) {
// ...
}
}| 1 | Must be a public class. |
| 2 | Must have a public, no-argument constructor (or a default constructor). |
| The @RegisterColumnMapperFactory annotation may be repeated multiple times on the same type or method to register multiple factories. |
13.5.5. @RegisterBeanMapper
Use @RegisterBeanMapper to register a BeanMapper for a bean class:
public interface UserDao {
@SqlQuery("SELECT * FROM users")
@RegisterBeanMapper(User.class)
List<User> list();
}Using the prefix attribute causes the bean mapper to map only those columns
that begin with the prefix:
public interface UserDao {
@SqlQuery("SELECT u.id u_id, u.name u_name, r.id r_id, r.name r_name " +
"FROM users u LEFT JOIN roles r ON u.role_id = r.id")
@RegisterBeanMapper(value = User.class, prefix = "u")
@RegisterBeanMapper(value = Role.class, prefix = "r")
Map<User,Role> getRolesPerUser();
}In this example, the User mapper will map the columns u_id and u_name into
the User.id and User.name properties. Likewise for r_id and r_name into
Role.id and Role.name, respectively.
| The @RegisterBeanMapper annotation may be repeated (as demonstrated above) on the same type or method to register multiple bean mappers. |
13.5.6. @RegisterConstructorMapper
Use @RegisterConstructorMapper to register a ConstructorMapper for classes that are instantiated with all properties through the constructor.
public interface UserDao {
@SqlQuery("SELECT * FROM users")
@RegisterConstructorMapper(User.class)
List<User> list();
}Using the prefix attribute causes the constructor mapper to only map those
columns that begin with the prefix:
public interface UserDao {
@SqlQuery("SELECT u.id u_id, u.name u_name, r.id r_id, r.name r_name " +
"FROM users u LEFT JOIN roles r ON u.role_id = r.id")
@RegisterConstructorMapper(value = User.class, prefix = "u")
@RegisterConstructorMapper(value = Role.class, prefix = "r")
Map<User,Role> getRolesPerUser();
}In this example, the User mapper will map the columns u_id and u_name into
the id and name parameters of the User constructor. Likewise for r_id
and r_name into id and name parameters of the Role constructor,
respectively.
| The @RegisterConstructorMapper annotation may be repeated multiple times on the same type or method to register multiple constructor mappers. |
13.5.7. @RegisterFieldMapper
Use @RegisterFieldMapper to register a FieldMapper for a given class.
public interface UserDao {
@SqlQuery("SELECT * FROM users")
@RegisterFieldMapper(User.class)
List<User> list();
}Using the prefix attribute causes the field mapper to only map those columns
that begin with the prefix:
public interface UserDao {
@SqlQuery("SELECT u.id u_id, u.name u_name, r.id r_id, r.name r_name " +
"FROM users u LEFT JOIN roles r ON u.role_id = r.id")
@RegisterFieldMapper(value = User.class, prefix = "u")
@RegisterFieldMapper(value = Role.class, prefix = "r")
Map<User,Role> getRolesPerUser();
}In this example, the User mapper will map the columns u_id and u_name into
the User.id and User.name fields. Likewise for r_id and r_name into the
Role.id and Role.name fields, respectively.
| The @RegisterConstructorMapper annotation may be repeated multiple times on the same type or method to register multiple constructor mappers. |
13.6. Other SQL Object annotations
13.6.1. @GetGeneratedKeys
Some SQL statements will cause data to be generated on your behalf at the database, e.g. a table with an auto-generated primary key, or a primary key selected from a sequence. The @GetGeneratedKeys annotation may be used to return the keys generated from the SQL statement:
The @GetGeneratedKeys annotation tells Jdbi that the return value should be generated key from the SQL statement, instead of the update count.
public interface UserDao {
@SqlUpdate("INSERT INTO users (id, name) VALUES (nextval('user_seq'), ?)")
@GetGeneratedKeys("id")
long insert(String name);
}Multiple columns may be generated and returned:
public interface UserDao {
@SqlUpdate("INSERT INTO users (id, name, created_on) VALUES (nextval('user_seq'), ?, now())")
@GetGeneratedKeys({"id", "created_on"})
@RegisterBeanMapper(IdCreateTime.class)
IdCreateTime insert(String name);
}| Databases vary in support for generated keys. Some support only one generated key column per statement, and some (such as Postgres) can return the entire row. You should check your database vendor’s documentation before relying on this behavior. |
@SqlBatch also supports the annotation:
public void sqlObjectBatchKeys() {
db.useExtension(UserDao.class, dao -> {
List<User> users = dao.createUsers("Alice", "Bob", "Charlie");
assertThat(users).hasSize(3);
assertThat(users.get(0).id).isOne();
assertThat(users.get(0).name).isEqualTo("Alice");
assertThat(users.get(1).id).isEqualTo(2);
assertThat(users.get(1).name).isEqualTo("Bob");
assertThat(users.get(2).id).isEqualTo(3);
assertThat(users.get(2).name).isEqualTo("Charlie");
});
}
public interface UserDao {
@SqlBatch("INSERT INTO users (name) VALUES(?)")
@GetGeneratedKeys
List<User> createUsers(String... names);
}When using @SqlBatch, the @GetGeneratedKeys annotations tells SQL Object that the return value should be the generated keys from each SQL statement, instead of the update count.
public interface UserDao {
@SqlBatch("INSERT INTO users (id, name) VALUES (nextval('user_seq'), ?)")
@GetGeneratedKeys("id")
long[] bulkInsert(List<String> names); (1)
}| 1 | Returns the generated ID for each inserted name. |
Multiple columns may be generated and returned in this way:
public interface UserDao {
@SqlBatch("INSERT INTO users (id, name, created_on) VALUES (nextval('user_seq'), ?, now())")
@GetGeneratedKeys({"id", "created_on"})
@RegisterBeanMapper(IdCreateTime.class)
List<IdCreateTime> bulkInsert(String... names);
}| Postgres supports additional functionality when returning generated keys. See PostgreSQL for more details. |
13.6.2. @SqlLocator
When SQL statements grow in complexity, it may be cumbersome to provide the statements as Java strings in the SQL method annotations.
| Jdbi supports the Java Textblock construct available in Java 15 and later. Using a text block is an elegant way to specify multi-line SQL statements. |
Jdbi provides annotations that let you configure external locations to load SQL statements.
-
@UseAnnotationSqlLocator - use annotation value of the SQL method annotations (this is the default behavior)
-
@UseClasspathSqlLocator - loads SQL from a file on the classpath, based on the package and name of the SQL Object interface type.
package com.foo;
@UseClasspathSqlLocator
interface BarDao {
// loads classpath resource com/foo/BarDao/query.sql
@SqlQuery
void query();
}@UseClasspathSqlLocator is implemented using the ClasspathSqlLocator, as described above.
ClasspathSqlLocator loads a file unchanged by default. Using the @UseClasspathSqlLocator annotation will strip out comments by default! This may lead to unexpected behavior, e.g. SQL Server uses the # character to denote temporary tables. This can be controlled with the stripComments annotation attribute.
|
package com.foo;
@UseClasspathSqlLocator(stripComments=false)
interface BarDao {
// loads classpath resource com/foo/BarDao/query.sql without stripping comment lines
@SqlQuery
void query();
}-
The jdbi-stringtemplate4 module provides @UseStringTemplateSqlLocator, a SqlLocator, which can load SQL templates from StringTemplate 4 files on the classpath.
-
The jdbi-freemarker module provides @UseFreemarkerSqlLocator, which can load SQL templates from Freemarker files on the classpath.
13.6.3. @CreateSqlObject
Use the @CreateSqlObject annotation to reuse a SQL Object type within another object.
This is an example where a SQL update defined in a different SQL Object type is executed as part of a transaction:
public interface Bar {
@SqlUpdate("INSERT INTO bar (name) VALUES (:name)")
@GetGeneratedKeys
int insert(@Bind("name") String name);
}
public interface Foo {
@CreateSqlObject
Bar createBar();
@SqlUpdate("INSERT INTO foo (bar_id, name) VALUES (:bar_id, :name)")
void insert(@Bind("bar_id") int barId, @Bind("name") String name);
@Transaction
default void insertBarAndFoo(String barName, String fooName) {
int barId = createBar().insert(barName);
insert(barId, fooName);
}
}The @CreateSqlObject annotation can also be used to process cursor-type objects inside interface default methods:
interface NestedDao {
@CreateSqlObject
UserDao userDao(); (1)
default List<String> getNames() {
try (Stream<String> stream = userDao().getNamesAsStream()) {
return stream.collect(Collectors.toList());
}
}
}
@Test
void testOnDemandNestedMethod() {
NestedDao dao = jdbi.onDemand(NestedDao.class);
List<String> result = dao.getNames();
assertThat(result).containsAll(names);
}| 1 | Returns a nested object that provides a stream of users. |
13.6.4. @Timestamped
You can annotate any statement with @Timestamped to bind an OffsetDateTime object representing the current time as now:
public interface Bar {
@Timestamped (1)
@SqlUpdate("INSERT INTO times(val) VALUES(:now)") (2)
int insert();
}| 1 | Bind a timestamp as now |
| 2 | Use the timestamp as a named binding. |
The binding name can be customized:
public interface Bar {
@Timestamped("timestamp")
@SqlUpdate("INSERT INTO times(val) VALUES(:timestamp)")
int insert();
}The TimestampedConfig config object allows setting the timezone for the timestamp.
13.6.5. @SingleValue
Sometimes, when using advanced SQL features like Arrays, a container type such as
int[] or List<Integer> can ambiguously mean either "a single SQL int[]" or
"a ResultSet of int".
Since arrays are not commonly used in normalized schemas, SQL Object assumes by default that you are collecting a ResultSet into a container object. You can annotate a return type as @SingleValue to override this.
For example, suppose we want to select a varchar[] column from a single row:
public interface UserDao {
@SqlQuery("SELECT roles FROM users WHERE id = ?")
@SingleValue
List<String> getUserRoles(long userId)
}Normally, Jdbi would interpret List<String> to mean that the mapped type is
String, and to collect all result rows into a list. The @SingleValue
annotation causes Jdbi to treat List<String> as the mapped type instead.
It’s tempting to use the @SingleValue annotation on an Optional<T> type , but usually this is not needed.
Optional<T> is implemented as a container of zero-or-one elements. Adding @SingleValue implies that the database itself has a column of a type like optional<varchar>.
|
The @SingleValue annotation can also be used on an array, collection or iterable method parameter. This causes SQL Object to bind the whole iterable as the parameter value. This is especially useful for @SqlBatch operations (often for a SQL Array parameter):
public interface UserDao {
@SqlBatch("INSERT INTO users (id, name, roles) VALUES (?, ?, ?)")
void bulkInsert(List<Long> ids,
List<String> names,
@SingleValue List<String> roles);
}In this example, each new row would get the same varchar[] value in the roles column.
13.6.6. Annotations for Map<K,V> Results
SQL Object methods may return Map<K,V> types (see Map.Entry mapping in
the Core API). In this scenario, each row is mapped to a Map.Entry<K,V>,
and the entries for each row are collected into a single Map instance.
| A mapper must be registered for both the key and value types. |
Gather master/detail join rows into a map, simply by registering mappers for the key and value types.
@SqlQuery("select u.id u_id, u.name u_name, p.id p_id, p.phone p_phone "
+ "from \"user\" u left join phone p on u.id = p.user_id")
@RegisterConstructorMapper(value = User.class, prefix = "u")
@RegisterConstructorMapper(value = Phone.class, prefix = "p")
Map<User, Phone> getMap();In the preceding example, the User mapper uses the "u" column name prefix, and
the Phone mapper uses "p". Since each mapper only reads the column with the
expected prefix, the respective id columns are unambiguous.
A unique index (e.g. by ID column) can be obtained by setting the key column name:
@SqlQuery("select * from \"user\"")
@KeyColumn("id")
@RegisterConstructorMapper(User.class)
Map<Integer, User> getAll();Set both the key and value column names to gather a two-column query into a map result:
@SqlQuery("select \"key\", \"value\" from config")
@KeyColumn("key")
@ValueColumn("value")
Map<String, String> getAll();All of the above examples assume a one-to-one key/value relationship.
What if there is a one-to-many relationship? Google Guava provides a Multimap
type, which supports mapping multiple values per key.
First, follow the instructions in the Google Guava section to install the GuavaPlugin.
Then, simply specify a Multimap return type instead of Map:
@SqlQuery("select u.id u_id, u.name u_name, p.id p_id, p.phone p_phone "
+ "from \"user\" u left join phone p on u.id = p.user_id")
@RegisterConstructorMapper(value = User.class, prefix = "u")
@RegisterConstructorMapper(value = Phone.class, prefix = "p")
Multimap<User, Phone> getMultimap();All the examples so far have been Map types where each row in the result set
is a single Map.Entry. However, what if the Map we want to return is
actually a single row or even a single column?
Jdbi’s MapMapper maps each row to a
Map<String, Object>, where column names are mapped to column values.
Jdbi’s default setting is to convert column names to lowercase for Map keys. This behavior can be
changed via the MapMappers config class.
|
By default, SQL Object treats Map return types as a collection of Map.Entry
values. Use the @SingleValue annotation to override this, so that the return
type is treated as a single value instead of a collection:
@SqlQuery("SELECT * FROM users WHERE id = ?")
@RegisterRowMapper(MapMapper.class)
@SingleValue
Map<String, Object> getById(long userId);The GenericMapMapperFactory,
provides the same feature but allows value types other than Object as long as a suitable ColumnMapper
is registered and all columns are of the same type:
@SqlQuery("SELECT 1.0 AS LOW, 2.0 AS MEDIUM, 3.0 AS HIGH")
@RegisterRowMapperFactory(GenericMapMapperFactory.class)
@SingleValue
Map<String, BigDecimal> getNumericLevels();
The PostgreSQL plugin provides an hstore to Map<String, String> column mapper. See hstore for more information.
|
13.6.7. @UseRowReducer
@SqlQuery methods that use join queries may reduce master-detail joins into one or more master-level objects. See ResultBearing.reduceRows() for an introduction to row reducers.
Consider a filesystem metaphor with folders and documents. In the join, we’ll
prefix folder columns with f_ and document columns with d_.
@RegisterBeanMapper(value = Folder.class, prefix = "f") (1)
@RegisterBeanMapper(value = Document.class, prefix = "d")
public interface DocumentDao {
@SqlQuery("SELECT " +
"f.id f_id, f.name f_name, " +
"d.id d_id, d.name d_name, d.contents d_contents " +
"FROM folders f LEFT JOIN documents d " +
"ON f.id = d.folder_id " +
"WHERE f.id = :folderId" +
"ORDER BY d.name")
@UseRowReducer(FolderDocReducer.class) (2)
Optional<Folder> getFolder(int folderId); (3)
@SqlQuery("SELECT " +
"f.id f_id, f.name f_name, " +
"d.id d_id, d.name d_name, d.contents d_contents " +
"FROM folders f LEFT JOIN documents d " +
"ON f.id = d.folder_id " +
"ORDER BY f.name, d.name")
@UseRowReducer(FolderDocReducer.class) (2)
List<Folder> listFolders(); (3)
class FolderDocReducer implements LinkedHashMapRowReducer<Integer, Folder> { (4)
@Override
public void accumulate(Map<Integer, Folder> map, RowView rowView) {
Folder f = map.computeIfAbsent(rowView.getColumn("f_id", Integer.class), (5)
id -> rowView.getRow(Folder.class));
if (rowView.getColumn("d_id", Integer.class) != null) { (6)
f.getDocuments().add(rowView.getRow(Document.class));
}
}
}
}| 1 | In this example, we register the folder and document mappers with a
prefix, so that each mapper only looks at the columns with that prefix.
These mappers are used indirectly by the row reducer in the
getRow(Folder.class) and getRow(Document.class) calls. |
| 2 | Annotate the method with @UseRowReducer, and specify the RowReducer
implementation class. |
| 3 | The same RowReducer implementation may be used for both single- and
multi-master-record queries. |
| 4 | LinkedHashMapRowReducer
is an abstract RowReducer implementation that uses a LinkedHashMap as the result
container, and returns the values() collection as the result. |
| 5 | Get the Folder for this row from the map by ID, or create it if not in the map. |
| 6 | Confirm this row has a document (this is a left join) before mapping a document and adding it to the folder. |
13.6.8. @RegisterCollector and @RegisterCollectorFactory
Convenience annotations to register a Collector for a SqlObject method.
@RegisterCollectorFactory allows registration of a factory that returns a collector instance and @RegisterCollector registers a collector implementation:
public interface RegisterCollectorDao {
@RegisterCollector(StringConcatCollector.class)
@SqlQuery("select i from i order by i asc")
String selectWithCollector();
@RegisterCollectorFactory(StringConcatCollectorFactory.class)
@SqlQuery("select i from i order by i asc")
String selectWithCollectorFactory();
}
class StringConcatCollectorFactory implements CollectorFactory {
@Override
public boolean accepts(Type containerType) {
return containerType == String.class;
}
@Override
public Optional<Type> elementType(Type containerType) {
return Optional.of(Integer.class);
}
@Override
public Collector<Integer, List<Integer>, String> build(Type containerType) {
return Collector.of(
ArrayList::new,
List::add,
(x, y) -> {
x.addAll(y);
return x;
},
i -> i.stream().map(Object::toString).collect(Collectors.joining(" ")));
}
}
class StringConcatCollector implements Collector<Integer, List<Integer>, String> {
@Override
public Supplier<List<Integer>> supplier() {
return ArrayList::new;
}
@Override
public BiConsumer<List<Integer>, Integer> accumulator() {
return List::add;
}
@Override
public BinaryOperator<List<Integer>> combiner() {
return (a, b) -> {
a.addAll(b);
return a;
};
}
@Override
public Function<List<Integer>, String> finisher() {
return i -> i.stream().map(Object::toString).collect(Collectors.joining(" "));
}
@Override
public Set<Characteristics> characteristics() {
return Collections.emptySet();
}
}The element and result types are inferred from the concrete Collector<Element, ?, Result> implementation’s type parameters. See Collectors for more details.
13.6.9. Other SQL Object annotations
Jdbi provides many additional annotations out of the box:
-
org.jdbi.v3.sqlobject.config provides annotations for things that can be configured at the Jdbi or Handle level. This includes registration of mappers and arguments, and for configuring SQL statement rendering and parsing.
-
org.jdbi.v3.sqlobject.customizer provides annotations for binding parameters, defining attributes, and controlling the fetch behavior of the statement’s result set.
-
org.jdbi.v3.jpa provides the @BindJpa annotation, for binding properties to column according to JPA
@Columnannotations. -
org.jdbi.v3.sqlobject.locator provides annotations that configure Jdbi to load SQL statements from an alternative source, e.g. a file on the classpath.
-
org.jdbi.v3.sqlobject.statement provides the @MapTo annotation, which is used for dynamically specifying the mapped type at the time the method is invoked.
-
org.jdbi.v3.stringtemplate4 provides annotations that configure Jdbi to load SQL from StringTemplate 4
.stgfiles on the classpath, and/or to parse SQL templates using the ST4 template engine. -
org.jdbi.v3.sqlobject.transaction provides annotations for transaction management in a SQL object. See SQL Object Transactions for details.
The SQL Object framework is built on top of the Jdbi Extension framework which can be extended with user-defined annotations. See the extension framework annotation documentation for an overview on how to build your own annotations.
13.6.10. Annotations and Inheritance
SQL Objects inherit methods and annotations from the interfaces they extend:
package com.app.dao;
@UseClasspathSqlLocator (1) (2)
public interface CrudDao<T, ID> {
@SqlUpdate (3)
void insert(@BindBean T entity);
@SqlQuery (3)
Optional<T> findById(ID id);
@SqlQuery
List<T> list();
@SqlUpdate
void update(@BindBean T entity);
@SqlUpdate
void deleteById(ID id);
}| 1 | See @SqlLocator. |
| 2 | Class annotations are inherited by subtypes. |
| 3 | Method and parameter annotations are inherited by subtypes, unless the subtype overrides the method. |
package com.app.contact;
@RegisterBeanMapper(Contact.class)
public interface ContactDao extends CrudDao<Contact, Long> {}package com.app.account;
@RegisterConstructorMapper(Account.class)
public interface AccountDao extends CrudDao<Account, UUID> {}In this example we’re using the @UseClasspathSqlLocator annotation, so each
method will use SQL loaded from the classpath. Thus, ContactDao methods will
use SQL from:
-
/com/app/contact/ContactDao/insert.sql -
/com/app/contact/ContactDao/findById.sql -
/com/app/contact/ContactDao/list.sql -
/com/app/contact/ContactDao/update.sql -
/com/app/contact/ContactDao/deleteById.sql
Whereas AccountDao will use SQL from:
-
/com/app/account/AccountDao/insert.sql -
/com/app/account/AccountDao/findById.sql -
/com/app/account/AccountDao/list.sql -
/com/app/account/AccountDao/update.sql -
/com/app/account/AccountDao/deleteById.sql
Suppose Account used name()-style accessors instead of getName(). In that
case, we’d want AccountDao to use @BindMethods instead of @BindBean.
Let’s override those methods with the right annotations:
package com.app.account;
@RegisterConstructorMapper(Account.class)
public interface AccountDao extends CrudDao<Account, UUID> {
@Override
@SqlUpdate (1)
void insert(@BindMethods Account entity);
@Override
@SqlUpdate (1)
void update(@BindMethods Account entity);
}| 1 | Method annotations are not inherited on override, so we must duplicate those we want to keep. |
13.7. Combining SQL Object and the core API
The SQL Object extension uses the same core API as programmatic SQL operations. There is an underlying Handle object that is used to execute the SQL methods.
A SQL Object type can extend the SqlObject mixin interface to get access to the handle. It also exposes a number of operations that can be used to mix declarative SQL Object methods with programmatic core API code:
public interface SomeDao extends SqlObject {
// ...
}
void mixedCode() {
SomeDao dao = jdbi.onDemand(SomeDao.class);
dao.withHandle(handle -> {
handle.createQuery("SELECT * from users").mapTo(User.class).list();
})
}This interface gives access to the handle and offers SqlObject#withHandle() and SqlObject#useHandle() methods that execute callback code using the same handle object as the methods on the SQL object interface itself.
| This is most useful for SQL object instances that get passed from other code, have been created from Jdbi#onDemand() or use default methods. Any object that was created using the Handle#attach() method will return the handle it was attached to. |
13.7.1. Using default Methods with the SqlObject mixin
Occasionally a use case comes up where SQL Method annotations don’t fit. In these situations, it is possible to "drop down" to the Core API using interface
default methods and the SqlObject mixin interface:
public interface SplineDao extends SqlObject {
default void reticulateSplines(Spline spline) {
Handle handle = getHandle();
// do tricky stuff using the Core API
}
}Default methods can also be used to group multiple SQL operations into a single method call:
public interface ContactPhoneDao {
@SqlUpdate("INSERT INTO contacts (id, name) VALUES (nextval('contact_id'), :name)")
long insertContact(@BindBean Contact contact);
@SqlBatch("INSERT INTO phones (contact_id, type, phone) VALUES (:contactId, :type, :phone)")
void insertPhone(long contactId, @BindBean Iterable<Phone> phones);
default long insertFullContact(Contact contact) {
long id = insertContact(contact);
insertPhone(id, contact.getPhones());
return id;
}
}13.8. SQL Object Transactions
Methods on a SQL object can have a @Transaction annotation:
@Transaction
@SqlQuery("SELECT * FROM users WHERE id=:id")
Optional<User> findUserById(int id);SQL methods with a @Transaction annotation may optionally specify a transaction isolation level:
@Transaction(TransactionIsolationLevel.READ_COMMITTED)
@SqlUpdate("INSERT INTO USERS (name) VALUES (:name)")
void insertUser(String name);Similar to the Jdbi#inTransaction() and Jdbi#useTransaction() operations in the core API, transactions are not nested. If a method, that has been annotated with @Transaction, calls another method that is annotated as well (e.g. through an interface default method), then the same transaction will be reused, and it will be committed when the outer transaction ends.
Nested method calls must either use the same transaction isolation level or inner methods must not specify any transaction level. In that case, the transaction level of the outer transaction maintained.
@Transaction(TransactionIsolationLevel.READ_UNCOMMITTED)
default void outerMethodCallsInnerWithSameLevel() {
// this works: isolation levels agree
innerMethodSameLevel();
}
@Transaction(TransactionIsolationLevel.READ_UNCOMMITTED)
default void innerMethodSameLevel() {}
@Transaction(TransactionIsolationLevel.READ_COMMITTED)
default void outerMethodWithLevelCallsInnerMethodWithNoLevel() {
// this also works: inner method doesn't specify a level, so the outer method controls.
innerMethodWithNoLevel();
}
@Transaction
default void innerMethodWithNoLevel() {}
@Transaction(TransactionIsolationLevel.REPEATABLE_READ)
default void outerMethodWithOneLevelCallsInnerMethodWithAnotherLevel() throws TransactionException {
// error! inner method specifies a different isolation level.
innerMethodWithADifferentLevel();
}
@Transaction(TransactionIsolationLevel.SERIALIZABLE)
default void innerMethodWithADifferentLevel() {}13.8.1. Executing multiple SQL operations in a single transaction
A SQL object method uses its own transaction. Multiple method calls can be grouped together to use a shared transaction:
For an existing handle, attach the SQL object inside the transaction:
public interface UserDao {
@Transaction
@SqlUpdate("INSERT INTO users VALUES (:id, :name)")
void createUser(int id, String name);
}
public void createUsers(Handle handle) {
handle.useTransaction(transactionHandle -> {
UserDao dao = transactionHandle.attach(UserDao.class);
// both inserts happen in the same transaction
dao.createUser(1, "Alice");
dao.createUser(2, "Bob");
}
}As an alternative, the Transactional mixin interface can be used to provide transaction support on a SQL object.
Similar to the SqlObject interface, it gives access to all transaction related methods on the Handle and offers the same callbacks as the Handle itself.
With this mixin interface, the Transactional#useTransaction() and Transactional#inTransaction() methods group statements into a single transaction by using a callback:
public interface UserDao extends Transactional<UserDao> {
@Transaction
@SqlUpdate("INSERT INTO users VALUES (:id, :name)")
void createUser(int id, String name);
}
public void createUsers(Jdbi jdbi) {
UserDao dao = jdbi.onDemand(UserDao.class);
dao.useTransaction(transactionDao -> {
// both inserts happen in the same transaction
transactionDao.createUser(1, "Alice");
transactionDao.createUser(2, "Bob");
});
}Nested calls can be used as well:
public interface UserDao extends Transactional<UserDao> {
@Transaction
@SqlUpdate("INSERT INTO users VALUES (:id, :name)")
void createUser(int id, String name);
}
public void createUsers(Jdbi jdbi) {
UserDao dao = jdbi.onDemand(UserDao.class);
dao.useTransaction(transactionDao1 -> {
// both inserts happen in the same transaction
transactionDao1.createUser(1, "Alice");
transactionDao1.useTransaction(transactionDao2 -> {
transactionDao2.createUser(2, "Bob");
});
});
}SQL object calls and core API calls can be mixed:
public interface UserDao extends Transactional<UserDao> {
@Transaction
@SqlUpdate("INSERT INTO users VALUES (:id, :name)")
void createUser(int id, String name);
}
public void createUsers(Jdbi jdbi) {
UserDao dao = jdbi.onDemand(UserDao.class);
dao.useTransaction(transactionDao -> {
// inserts happen in the same transaction
transactionDao.createUser(1, "Alice");
transactionDao.createUser(2, "Bob");
// this insert as well
transactionDao.getHandle().useTransaction(transactionHandle ->
transactionHandle.createUpdate("USERT INTO users VALUES (:id, :name)")
.bind("id", 3)
.bind("name", "Charlie")
.execute();
}
}
}14. Miscellaneous
14.1. Generated Keys
An Update or PreparedBatch may automatically generate keys. These keys are treated separately from normal results. Depending on your database and configuration, the entire inserted row may be available.
| There is a lot of variation between databases supporting this feature so please test this feature’s interaction with your database thoroughly. |
In PostgreSQL, the entire row is available, so you can immediately map your inserted names back to full User objects! This avoids the overhead of separately querying after the insert completes.
Consider the following table:
public static class User {
final int id;
final String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
@BeforeEach
public void setUp() {
db = pgExtension.getJdbi();
db.useHandle(h -> h.execute("CREATE TABLE users (id SERIAL PRIMARY KEY, name VARCHAR)"));
db.registerRowMapper(ConstructorMapper.factory(User.class));
}You can get generated keys in the fluent style:
public void fluentInsertKeys() {
db.useHandle(handle -> {
User data = handle.createUpdate("INSERT INTO users (name) VALUES(?)")
.bind(0, "Data")
.executeAndReturnGeneratedKeys()
.mapTo(User.class)
.one();
assertThat(data.id).isOne(); // this value is generated by the database
assertThat(data.name).isEqualTo("Data");
});
}14.2. Qualified Types
Sometimes the same Java object can correspond to multiple data types in a database. For example,
a String could be varchar plaintext, nvarchar text, json data, etc., all with different handling requirements.
QualifiedType allows you to add such context to a Java type:
QualifiedType.of(String.class).with(Json.class);This QualifiedType still represents the String type, but qualified with the @Json annotation.
It can be used in a way similar to GenericType, to make components
handling values (mainly ArgumentFactories and ColumnMapperFactories) perform their work differently,
and to have the values handled by different implementations altogether:
@Json
public class JsonArgumentFactory extends AbstractArgumentFactory<String> {
@Override
protected Argument build(String value, ConfigRegistry config) {
// do something specifically for json data
}
}Once registered, this @Json qualified factory will receive only @Json String values.
Other factories not qualified as such will not receive this value:
QualifiedType<String> json = QualifiedType.of(String.class).with(Json.class);
query.bindByType("jsonValue", "{\"foo\":1}", json);| Jdbi chooses factories to handle values by exactly matching their qualifiers. It’s up to the factory implementations to discriminate on the type of the value afterward. |
Qualifiers are implemented as Annotations. This allows factories to independently inspect values for qualifiers at the source,
such as on their Class, to alter their own behavior or to requalify a value
and have it re-evaluated by Jdbi’s lookup chain.
|
| Qualifiers being annotations does not mean they inherently activate their function when placed in source classes. Each feature decides its own rules regarding their use. |
Arguments can only be qualified for binding via bindByType calls, not regular
bind or update.execute(Object...). Also, arrays cannot be qualified.
|
These features currently make use of qualified types:
-
@NVarcharand@MacAddr(the latter injdbi3-postgres) bind and map Strings asnvarcharandmacaddrrespectively, instead of the usualvarchar. -
jdbi3-postgresoffers HStore. -
BeanMapper, @BindBean, @RegisterBeanMapper,mapTobean(), andbindBean()respect qualifiers on getters, setters, and setter parameters. -
ConstructorMapperand @RegisterConstructorMapper respect qualifiers on constructor parameters. -
@BindMethods and
bindMethods()respect qualifiers on methods. -
@BindFields, @RegisterFieldMapper,
FieldMapperandbindFields()respect qualifiers on fields. -
SqlObjectrespects qualifiers on methods (applies them to the return type) and parameters.-
on parameters of type Consumer<T>, qualifiers are applied to the
T.
-
-
@BindJpa and
JpaMapperrespect qualifiers on getters and setters. -
@BindKotlin,bindKotlin(), andKotlinMapperrespect qualifiers on constructor parameters, getters, setters, and setter parameters.
14.3. Query Templating
Binding query parameters, as described above, is excellent for sending a static set of parameters to the database engine. Binding ensures that the parameterized query string (... where foo = ?) is transmitted to the database without allowing hostile parameter values to inject SQL.
Bound parameters are not always enough. Sometimes a query needs complicated or structural changes before being executed, and parameters just don’t cut it. Templating (using a TemplateEngine) allows you to alter a query’s content with general String manipulations.
Typical uses for templating are optional or repeating segments (conditions and loops), complex variables such as comma-separated lists for IN clauses, and variable substitution for non-bindable SQL elements (like table names). Unlike argument binding, the rendering of attributes performed by TemplateEngines is not SQL-aware. Since they perform generic String manipulations, TemplateEngines can easily produce horribly mangled or subtly defective queries if you don’t use them carefully.
| Query templating is a common attack vector! Always prefer binding parameters to static SQL over dynamic SQL when possible. |
handle.createQuery("SELECT * FROM <TABLE> WHERE name = :n")
// -> "SELECT * FROM Person WHERE name = :n"
.define("TABLE", "Person")
// -> "SELECT * FROM Person WHERE name = 'MyName'"
.bind("n", "MyName");| Use a TemplateEngine to perform crude String manipulations on a query. Query parameters should be handled by Arguments. |
| TemplateEngines and SqlParsers operate sequentially: the initial String will be rendered by the TemplateEngine using attributes, then parsed by the SqlParser with Argument bindings. |
If the TemplateEngine outputs text matching the parameter format of the SqlParser, the parser will attempt to bind an Argument to it. This can be useful to e.g. have named parameters of which the name itself is also a variable, but can also cause confusing bugs:
String paramName = "arg";
handle.createQuery("SELECT * FROM Foo WHERE bar = :<attr>")
.define("attr", paramName)
// ...
.bind(paramName, "baz"); // <- does not need to know the parameter's name ("arg")!handle.createQuery("SELECT * FROM emotion WHERE emoticon = <sticker>")
.define("sticker", ":-)") // -> "... WHERE emoticon = :-)"
.mapToMap()
// exception: no binding/argument named "-)" present
.list();Bindings and definitions are usually separate. You can link them in a limited manner
using the stmt.defineNamedBindings() or @DefineNamedBindings customizers.
For each bound parameter (including bean properties), this will define a boolean which is true if the
binding is present and not null. You can use this to
craft conditional updates and query clauses.
For example,
class MyBean {
long id();
String getA();
String getB();
Instant getModified();
}
handle.createUpdate("UPDATE mybeans SET <if(a)>a = :a,<endif> <if(b)>b = :b,<endif> modified=now() WHERE id=:id")
.bindBean(mybean)
.defineNamedBindings()
.execute();Also see the section about TemplateEngine.
14.3.1. ClasspathSqlLocator
You may find it helpful to store your SQL templates in individual files on the classpath, rather than in string inside Java code.
The ClasspathSqlLocator converts Java type and method names into classpath locations,
and then reads, parses, and caches the loaded statements.
// reads classpath resource com/foo/BarDao/query.sql
ClasspathSqlLocator.create().locate(com.foo.BarDao.class, "query");
// same resource as above
ClasspathSqlLocator.create().locate("com.foo.BarDao.query");By default, any comments in the loaded file are left untouched. Comments can be stripped out by
instantiating the ClasspathSqlLocator with the removingComments() method:
// reads classpath resource com/foo/BarDao/query.sql, stripping all comments
ClasspathSqlLocator.removingComments().locate(com.foo.BarDao.class, "query");
// same resource as above
ClasspathSqlLocator.removingComments().locate("com.foo.BarDao.query");Multiple comment styles are supported:
-
C-style (
/* ... */and//to the end of the line) -
SQL style (
--to the end of the line) -
shell style (
#to the end of the line; except when followed immediately by the>character; this is required for the Postgres#>and#>>operators).
Each piece of core or extension that wishes to participate in
configuration defines a configuration class, for example the SqlStatements
class stores SqlStatement related configuration. Then, on any Configurable context
(like a Jdbi or Handle) you can change configuration in a type safe way:
jdbi.getConfig(SqlStatements.class).setUnusedBindingAllowed(true);
jdbi.getConfig(Arguments.class).register(new MyTypeArgumentFactory());
jdbi.getConfig(Handles.class).setForceEndTransactions(true);
// Or, if you have a bunch of work to do:
jdbi.configure(RowMappers.class, rm -> {
rm.register(new TypeARowMapperFactory();
rm.register(new TypeBRowMapperFactory();
});14.4. Statement caching
Jdbi caches statement information in multiple places:
-
preparsed SQL where placeholders have been replaced.
-
rendered statement templates if the template engine supports it.
Caching can dramatically speed up the execution of statements. By default, Jdbi uses a simple LRU in-memory cache with 1,000 entries. This cache is sufficient for most use cases.
For applications than run a lot of different SQL operations, it is possible to use different cache implementations. Jdbi provides a cache SPI for this.
The following cache implementations are included:
-
jdbi3-caffeine-cache- using the Caffeine cache library. This used to be the default cache up to version 3.36.0 -
jdbi3-noop-cache, - disables caching. This is useful for testing and debugging.
A cache module can provide a plugin to enable it. Only one plugin can be in use at a time (last one installed wins):
// use the caffeine cache library
jdbi.installPlugin(new CaffeineCachePlugin());14.4.1. Using custom cache instances
The default cache instances are installed when the Jdbi object is created. When using a cache plugin, the implementation is changed but only very few aspects of the cache can be modified.
Full customization is possible by creating the cache outside Jdbi and then use a cache builder adapter:
// create a custom Caffeine cache
JdbiCacheBuilder customCacheBuilder = new CaffeineCacheBuilder(
Caffeine.newBuilder()
.maximumSize(100_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.recordStats());
SqlStatements config = jdbi.getConfig(SqlStatements.class);
config.setTemplateCache(customCacheBuilder));
config.setSqlParser(new ColonPrefixSqlParser(customCacheBuilder));When setting the caches explicitly, no cache plugin needs to be installed.
| If the underlying cache library exposes per-cache statistics, these can be accessed through the SqlStatements#cacheStats() and CachingSqlParser#cacheStats() methods. |
15. Testing
The official test support from Jdbi is in the jdbi-testing package. There are a number of additional JUnit 5 extensions in the jdbi-core test artifact. These are only intended for Jdbi internal use and not part of the official, public API.
|
15.1. JUnit 4
The jdbi3-testing artifact provides JdbiRule
class which implements TestRule and can be used with the Rule and ClassRule annotations.
It provides helpers for writing JUnit 4 tests integrated with a managed database instance. This makes writing unit tests quick and easy! You must remember to include the database dependency itself, for example to get a pure H2 Java database:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>2.1.212</version>
<scope>test</scope>
</dependency>JUnit 4 supports the OTJ embedded postgres component, which needs to be included when using Postgres:
<dependency>
<groupId>com.opentable.components</groupId>
<artifactId>otj-pg-embedded</artifactId>
<version>1.0.1</version>
<scope>test</scope>
</dependency>15.2. JUnit 5
The jdbi3-testing artifact provides JdbiExtension for JUnit 5 based tests.
It supports both the @RegisterExtension and @ExtendWith annotations.
When using @RegisterExtension, the extensions can be customized further:
public class Test {
@RegisterExtension
public JdbiExtension h2Extension = JdbiExtension.h2()
withPlugin(new SqlObjectPlugin());
@Test
public void testWithJunit5() {
Jdbi jdbi = h2Extension.getJdbi();
Handle handle = h2Extension.openHandle();
// ...
}
}The JdbiExtension and all its database specific subclasses can be registered as instance fields or as class-level (static) fields.
When registered as an instance field, each test will get a new Jdbi instance. The in-memory database specific subclasses (H2, SQLite or HsqlDB with the generic extension) will reset their content and provide a new instance.
When registered as a static field, the extension will be initialized before all test methods are executed. All tests share the same extension instance and its associated fields. The in-memory database specific subclasses will retain their contents across multiple tests.
The javadoc page for JdbiExtension contains additional information on how to customize a programmatically registered instance.
When using the @ExtendWith declarative extension, test methods can access the Jdbi and Handle objects through method parameters:
@ExtendWith(JdbiH2Extension.class)
public class Test {
@Test
public void testWithJunit5(Jdbi jdbi, Handle handle) {
// ...
}
}The instances injected are the same instances as returned by getJdbi() and getSharedHandle().
Currently supported databases:
-
Postgres - JdbiPostgresExtension, JdbiExternalPostgresExtension, JdbiOtjPostgresExtension
-
Generic JDBC database support - JdbiGenericExtension. This is a minimal extension that can support any database that support JDBC. The driver for the database must be on the classpath. All database management (schema creation, DDL object management etc.) must be done by the calling code.
-
Testcontainers - JdbiTestcontainersExtension. See Using Testcontainers for detailed documentation.
Support for other databases wanted!
The JdbiExtension provides a number of convenience methods:
public class JdbiExtension {
public JdbiExtension postgres(...) // new JdbiPostgresExtension(...)
public JdbiExtension externalPostgres(...) // new JdbiExternalPostgresExtension(...)
public JdbiExtension otjEmbeddedPostgres() // new JdbiOtjPostgresExtension()
public JdbiExtension h2() // new JdbiH2Extension()
public JdbiExtension sqlite() // new JdbiSqliteExtension()
}Additional functionality may be available by using the database specific implementation classes directly. For most common use cases, the convenience methods should suffice.
15.2.1. Testing with H2
The H2 database is one of the most popular choices for embedded testing. The JdbiH2Extension class allows for a few additional customizations:
// JdbiH2Extension(String) constructor allows H2 options
// JDBC URL is jdbc:h2:mem:<UUID>;MODE=MySQL
JdbiH2Extension extension = new JdbiH2Extension("MODE=MySQL");
// set H2 user
extension.withUser("h2-user");
// set H2 user and password
extension.withCredentials("h2-user", "h2-password");15.2.2. Testing with Postgres
Postgres is supported through multiple test classes:
-
JdbiPostgresExtension manages a local database on the host. It uses the pg-embedded library that can spin up Postgres instances on various OS and architectures. This is the fastest way to get to a Postgres instance. Most of the Jdbi test classes that use Postgres use this extension.
-
JdbiExternalPostgresExtension supports an external Postgres database and can run tests against any local or remote database.
-
JdbiOtjPostgresExtension supports the OpenTable Java Embedded PostgreSQL component.
15.3. Using Testcontainers
The Testcontainers project provides a number of services as docker containers with a programmatic interface for JVM code. Jdbi supports JDBC type databases with the JdbiTestcontainersExtension:
@Testcontainers
class TestWithContainers {
@Container
static JdbcDatabaseContainer<?> dbContainer = new YugabyteDBYSQLContainer("yugabytedb/yugabyte");
@RegisterExtension
JdbiExtension extension = JdbiTestcontainersExtension.instance(dbContainer);
// ... test code using the yugabyte engine
}The JdbiTestcontainersExtension has built-in support to isolate each test method in a test class. The container can be declared as a static class member which speeds up test execution significantly.
There is built-in support for MySQL, MariaDB, TiDB, PostgreSQL, CockroachDB, YugabyteDB, ClickHouse, Oracle XE and Trino. It also supports the various compatible flavors (such as PostGIS for PostgreSQL).
15.3.1. Providing custom database information
The JdbiTestcontainersExtension creates a new database or schema (depending on the database engine) for each test. This speeds up test execution. In some cases (e.g. when using a not yet supported database engine or when using a custom docker image), it may be necessary to provide a custom instance of the TestcontainersDatabaseInformation class that describes how to manage a specific database engine.
Here are examples for MySQL and PostgreSQL:
// MySQL has only databases, no schemata. The Jdbi extension creates a new database
// for each test method.
private static final TestcontainersDatabaseInformation MYSQL = TestcontainersDatabaseInformation.of(
"root", // Testcontainers provides the 'root' superuser for MySQL instances.
null, // do not override the generated catalog name
null, // do not override the generated schema name (which is not used by MySQL)
// create a new database from the catalog name
(catalogName, schemaName) -> format("CREATE DATABASE %s", catalogName)
);
// PostgreSQL knows about schemata but needs to use the predefined "test" database.
// The Jdbi extension creates a new schema for each test method
private static final TestcontainersDatabaseInformation POSTGRES = TestcontainersDatabaseInformation.of(
null, // Use the default user that testcontainers provides
"test", // override the generated catalog name with 'test'
null, // do not override the generated schema name
// create a new schema from the schema name
(catalogName, schemaName) -> format("CREATE SCHEMA %s", schemaName)
);See the Javadoc for the TestcontainersDatabaseInformation class for further details.
The JdbiTestcontainersExtension provides the instance(TestcontainersDatabaseInformation, JdbcDatabaseContainer) method which uses a custom database information object:
@Testcontainers
class TestWithCustomContainer {
@Container
static JdbcDatabaseContainer<?> dbContainer = new PostgreSQLContainer<>(
DockerImageName.parse("custom-image").asCompatibleSubstituteFor("postgres"));
static final TestcontainersDatabaseInformation CUSTOM_DATABASE =
TestcontainersDatabaseInformation.of( ... custom setup ...);
@RegisterExtension
JdbiExtension extension = JdbiTestcontainersExtension.instance(CUSTOM_DATABASE, dbContainer);
// ... test code using the custom engine
}16. Third-Party Integration
16.1. Google Guava
This plugin adds support for the following types:
-
Optional<T>- registers an argument and mapper. Supports Optional for any wrapped typeTfor which a mapper / argument factory is registered. -
Most Guava collection and map types - see GuavaCollectors for a complete list of supported types.
To use this plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-guava</artifactId>
</dependency>Then install the plugin into the Jdbi instance:
jdbi.installPlugin(new GuavaPlugin());With the plugin installed, any supported Guava collection type can be returned from a SQL object method:
public interface UserDao {
@SqlQuery("select * from users order by name")
ImmutableList<User> list();
@SqlQuery("select * from users where id = :id")
com.google.common.base.Optional<User> getById(long id);
}16.2. H2 Database
This plugin configures Jdbi to correctly handle integer[] and uuid[] data
types in an H2 database.
This plugin is included with the core jar (but may be extracted to separate artifact in the future). Use it by installing the plugin into your Jdbi instance:
jdbi.installPlugin(new H2DatabasePlugin());16.3. JSON
The jdbi3-json module adds a @Json type qualifier that allows to store arbitrary Java objects as JSON data in your database.
The actual JSON (de)serialization code is not included. For that, you must install a backing plugin (see below).
Backing plugins will install the JsonPlugin for you.
You do not need to install it yourself or include the jdbi3-json dependency directly.
|
The feature has been tested with Postgres json columns
and varchar columns in H2 and Sqlite.
16.3.1. Jackson 2
This plugin provides JSON backing through Jackson 2.
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-jackson2</artifactId>
</dependency>jdbi.installPlugin(new Jackson2Plugin());
// optionally configure your ObjectMapper (recommended)
jdbi.getConfig(Jackson2Config.class).setMapper(myObjectMapper);
// now with simple support for Json Views if you want to filter properties:
jdbi.getConfig(Jackson2Config.class).setView(ApiProperty.class);16.3.2. Gson 2
This plugin provides JSON backing through Gson 2.
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-gson2</artifactId>
</dependency>jdbi.installPlugin(new Gson2Plugin());
// optional
jdbi.getConfig(Gson2Config.class).setGson(myGson);16.3.3. Moshi
This plugin provides JSON backing through Moshi.
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-moshi</artifactId>
</dependency>jdbi.installPlugin(new MoshiPlugin());
// optional
jdbi.getConfig(MoshiConfig.class).setMoshi(myMoshi);16.3.4. Operation
Any bound object qualified as @Json
will be converted by the registered
JsonMapper and requalified as
@EncodedJson String.
A corresponding @EncodedJson ArgumentFactory will then be called to store the JSON data,
allowing special JSON handling for your database to be implemented.
If none are found, a factory for plain String will be used instead, to handle the JSON as plaintext.
Mapping works just the same way, but in reverse: an output type qualified as @Json T will be fetched from a
@EncodedJson String or String ColumnMapper, and then passed through the JsonMapper.
Our PostgresPlugin provides qualified factories that will
bind/map the @EncodedJson String to/from json or jsonb-typed columns.
|
16.3.5. Usage
handle.execute("create table myjsons (id serial not null, value json not null)");SqlObject:
// any json-serializable type
class MyJson {}
// use @Json qualifier:
interface MyJsonDao {
@SqlUpdate("INSERT INTO myjsons (json) VALUES(:value)")
// on parameters
int insert(@Json MyJson value);
@SqlQuery("SELECT value FROM myjsons")
// on result types
@Json
List<MyJson> select();
}
// also works on bean or property-mapped objects:
class MyBean {
private final MyJson property;
@Json
public MyJson getProperty() { return ...; }
}With the Fluent API, you provide a QualifiedType<T> any place you’d normally provide a Class<T> or GenericType<T>:
QualifiedType<MyJson> qualifiedType = QualifiedType.of(MyJson.class).with(Json.class);
h.createUpdate("INSERT INTO myjsons(json) VALUES(:json)")
.bindByType("json", new MyJson(), qualifiedType)
.execute();
MyJson result = h.createQuery("SELECT json FROM myjsons")
.mapTo(qualifiedType)
.one();16.4. Immutables
Immutables is an annotation processor that generates value types based on simple interface descriptions. The value types naturally map very well to property binding and row mapping.
Immutables support is still experimental and does not yet support custom naming schemes.
We do support the configurable get, is, and set prefixes.
|
Just tell us about your types by installing the plugin and configuring your Immutables type:
jdbi.getConfig(JdbiImmutables.class).registerImmutable(MyValueType.class)
The configuration will both register appropriate RowMappers as well as configure the new bindPojo (or @BindPojo) binders:
@Value.Immutable
public interface Train {
String name();
int carriages();
boolean observationCar();
}
@Test
public void simpleTest() {
jdbi.getConfig(JdbiImmutables.class).registerImmutable(Train.class);
try (Handle handle = jdbi.open()) {
handle.execute("create table train (name varchar, carriages int, observation_car boolean)");
assertThat(
handle.createUpdate("insert into train(name, carriages, observation_car) values (:name, :carriages, :observationCar)")
.bindPojo(ImmutableTrain.builder().name("Zephyr").carriages(8).observationCar(true).build())
.execute())
.isOne();
assertThat(
handle.createQuery("select * from train")
.mapTo(Train.class)
.one())
.extracting("name", "carriages", "observationCar")
.containsExactly("Zephyr", 8, true);
}
}16.5. Freebuilder
Freebuilder is an annotation processor that generates value types based on simple interface or abstract class descriptions. Jdbi supports Freebuilder in much the same way that it supports Immutables.
| Freebuilder support is still experimental and may not support all Freebuilder implemented features. We do support both JavaBean style getters and setters as well as unprefixed getters and setters. |
Just tell us about your Freebuilder types by installing the plugin and
configuring your Freebuilder type:
jdbi.getConfig(JdbiFreebuilder.class).registerFreebuilder(MyFreeBuilderType.class)
The configuration will both register appropriate RowMappers as well as
configure the new bindPojo (or @BindPojo) binders:
@FreeBuilder
public interface Train {
String name();
int carriages();
boolean observationCar();
class Builder extends FreeBuildersTest_Train_Builder {}
}
@Test
public void simpleTest() {
jdbi.getConfig(JdbiFreeBuilders.class).registerFreeBuilder(Train.class);
try (Handle handle = jdbi.open()) {
handle.execute("create table train (name varchar, carriages int, observation_car boolean)");
Train train = new Train.Builder()
.name("Zephyr")
.carriages(8)
.observationCar(true)
.build();
assertThat(
handle.createUpdate("insert into train(name, carriages, observation_car) values (:name, :carriages, :observationCar)")
.bindPojo(train)
.execute())
.isOne();
assertThat(
handle.createQuery("select * from train")
.mapTo(Train.class)
.one())
.extracting("name", "carriages", "observationCar")
.containsExactly("Zephyr", 8, true);
}
}16.6. JodaTime
This plugin adds support for using joda-time’s DateTime type.
To use this plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-jodatime2</artifactId>
</dependency>Then install the plugin into the Jdbi instance:
jdbi.installPlugin(new JodaTimePlugin());16.7. Google Guice
The Guice module adds support for configuring and injecting Jdbi instances in applications and services that use the Google Guice dependency injection framework.
Guice support for Jdbi is split into two module types:
-
A Jdbi definition module extends the AbstractJdbiDefinitionModule class. Each of these modules creates a new Jdbi instance which is exposed into the Guice binding process using an annotation.
-
A Jdbi element configuration module extends the AbstractJdbiConfigurationModule. These modules contribute elements that are referenced in Jdbi definition modules.
| Jdbi definition modules are by far more common. Element configuration modules are completely optional. They are most useful in larger projects. |
16.7.1. JSR 330 vs. JEE 9+ annotations
For a long time, Java used the JSR-330 annotations in the javax.inject namespace to define dependency injections. The Java Enterprise Edition 9 specification updated the dependency injection specification to version 2.0, which changed the namespace to jakarta.inject.
The jdbi3-guice module supports all Google Guice releases since 5.x including 6.x (which uses javax.inject annotations) and 7.x (which uses jakarta.inject).
16.7.2. Definition modules
Every Jdbi instance is defined in its own Guice module which extends the AbstractJdbiDefinitionModule base class.
The annotation instance or class used on the constructor is used to bind the resulting Jdbi object:
class GuiceJdbiModule extends AbstractJdbiDefinitionModule {
public GuiceJdbiModule() {
super(GuiceJdbi.class);
}
@Override
protected void configureJdbi() {
// bind a custom row mapper
bindRowMapper().to(CustomRowMapper.class);
// bind a custom column mapper
bindColumnMapper().toInstance(new CustomColumnMapper());
// bind a Codec
bindCodec(String.class).to(Key.get(CustomStringCodec.class, Custom.class));
// bind a custom array type
bindArrayType(CustomArrayType.class).toInstance("custom_array");
// bind a jdbi plugin
bindPlugin().toInstance(new SqlObjectPlugin());
// bind a customizer
bindCustomizer().to(SpecialCustomizer.class);
}
}
class Application {
@Inject
@GuiceJdbi
private Jdbi jdbi;
public static void main(String ... args) {
Injector inj = Guice.createInjector(
new GuiceJdbiModule(),
) binder -> binder.bind(DataSource.class).annotatedWith(GuiceJdbi.class).toInstance(... data source instance ...);
);
inj.injectMembers(this);
}
}In this example, a new Jdbi object is defined using specific mappers and other customizations. The Jdbi object is exposed to Guice using the annotation passed on the module constructor (GuiceJdbi in the example). The AbstractJdbiDefinitionModule supports both annotation instances and classes, similar to Guice itself.
| A Jdbi definition module requires that a DataSource object is bound within Guice using the same annotation or annotation class as is passed into the module constructor. Creating this data source is outside the scope of a Jdbi definition module! |
When implementing the configureJdbi() method, a number of convenience methods are available as shown above. These methods return Guice LinkedBindingBuilder instances and allow the full range of bindings that guice supports (classes, instances, providers etc).
| Method | Type of binding | Jdbi function |
|---|---|---|
|
||
Each Jdbi definition module is completely independent and all definitions within the module only apply to the specific Jdbi instance.
16.7.3. Using Guice injection in Jdbi classes
The Jdbi related guice modules store the various related elements (mappers, codecs etc.) using Multibindings. As a result, it is not possible to use injection directly when constructing mapper instances.
The following example does not work:
class JdbiModule extends AbstractJdbiDefinitionModule {
public JdbiModule() {
super(Names.named("data"));
}
@Override
protected void configureJdbi() {
bindRowMapper().to(BrokenRowMapper.class);
bindColumnMapper().to(CustomStringMapper.class);
}
}
class CustomStringMapper implements ColumnMapper<String> {
@Override
public String map(ResultSet r, int columnNumber, StatementContext ctx) {
long x = r.getLong(columnNumber);
return (x > 1000) ? "Huge" : "Small";
}
}
class BrokenRowMapper implements RowMapper<DataRow> {
private final ColumnMapper<String> stringMapper;
@Inject
public BrokenRowMapper(CustomStringMapper stringMapper) {
this.stringMapper = stringMapper;
}
@Override
public DataRow map(ResultSet rs, StatementContext ctx) {
return new DataRow(rs.getInt("intValue"),
stringMapper.map(rs, "longValue", ctx));
}
}Guice will report an error that it cannot locate the CustomStringMapper instance. The Guice Jdbi integration manages mappers etc. as groups and the separate instances are not directly accessible for injection. The right way to compose mappers is using the Jdbi configuration (see JdbiConfig), which is configured through Guice:
class JdbiModule extends AbstractJdbiDefinitionModule {
public JdbiModule() {
super(Names.named("data"));
}
@Override
protected void configureJdbi() {
bindRowMapper().to(WorkingRowMapper.class);
bindColumnMapper(CustomStringMapper.TYPE).to(CustomStringMapper.class);
}
}
class CustomStringMapper implements ColumnMapper<String> {
public static QualifiedType<String> TYPE = QualifiedType.of(String.class).with(Names.named("data"));
@Override
public String map(ResultSet r, int columnNumber, StatementContext ctx) throws SQLException {
long x = r.getLong(columnNumber);
return (x > 1000) ? "Huge" : "Small";
}
}
class WorkingRowMapper implements RowMapper<DataRow> {
private ColumnMapper<String> stringMapper;
@Override
public void init(ConfigRegistry registry) {
this.stringMapper = registry.get(ColumnMappers.class).findFor(CustomStringMapper.TYPE)
.orElseThrow(IllegalStateException::new);
}
@Override
public DataRow map(ResultSet rs, StatementContext ctx) throws SQLException {
return new DataRow(rs.getInt("intValue"),
stringMapper.map(rs, "longValue", ctx));
}
}This limitation only applies to bindings that are made in through the various bindXXX() methods in Jdbi specific modules. Any other binding is available for injection into Jdbi elements:
class ThresholdMapper implements ColumnMapper<String> {
public static QualifiedType<String> TYPE = QualifiedType.of(String.class).with(Threshold.class);
private final long threshold;
// Injection of a named constant here.
@Inject
ThresholdMapper(@Threshold long threshold) {
this.threshold = threshold;
}
@Override
public String map(ResultSet r, int columnNumber, StatementContext ctx) throws SQLException {
long x = r.getLong(columnNumber);
return (x > threshold) ? "Huge" : "Small";
}
}
class JdbiModule extends AbstractJdbiDefinitionModule {
public JdbiModule() {
super(Data.class);
}
@Override
protected void configureJdbi() {
bindColumnMapper(CustomStringMapper.TYPE).to(CustomStringMapper.class);
}
}
Injector inj = Guice.createInjector(
new JdbiModule(),
// define injected constant here
binder -> binder.bindConstant().annotatedWith(Threshold.class).to(5000L);
)16.7.4. Jdbi customization using Guice
Many Jdbi specific settings can be configured through the bindXXX() methods available on Jdbi modules (row mappers, column mappers, codecs, plugins etc.)
However, there are additional features that may not be available through these methods. For these use cases, the GuiceJdbiCustomizer interface can be used.
Instances that implement this interface can be added to Jdbi modules using the bindCustomizer() method.
Every customizer will get the Jdbi instance passed at construction time and may modify any aspect before it gets exposed to other parts of the application.
class GuiceCustomizationModule extends AbstractJdbiDefinitionModule {
public GuiceCustomizationModule() {
super(Custom.class);
}
@Override
protected void configureJdbi() {
bindCustomizer().to(MyCustomizer.class);
}
}
class MyCustomizer implements GuiceJdbiCustomizer {
@Override
public void customize(Jdbi jdbi) {
// set the logger to use Slf4j
jdbi.setSqlLogger(new Slf4JSqlLogger());
}
}In combination with Jdbi configuration modules, these customizers allow easy enforcement of standard configurations for all Jdbi instances in larger projects.
16.7.5. Element configuration modules
| Element configuration modules are completely optional and should not be used when only a single Jdbi instance is required. They are intended to help with code organization in larger projects that have more complex needs. |
All bindings in a Jdbi module that defines a Jdbi object are local to that module. This is useful if all Jdbi related code can be grouped around the module. In larger projects, some parts of the code (and their Jdbi related elements such as row and column mappers) may be located in different part of the code base.
In larger projects, generic mappers should be available for multiple Jdbi instances. This leads often to a proliferation of small modules that only contain such generic code and is in turn imported into every code module that wants to use them.
To support modular code design, any part of a code base that wants to contribute Jdbi specific classes such as mappers to the overall system can use an element configuration module to expose these to all Jdbi instances in a project.
Jdbi element configuration modules extend AbstractJdbiConfigurationModule and can define mappers, plugins etc. similar to a Jdbi definition module. Anything that is registered in such a module is global and will be applied to all instances even if they are defined in another module.
class DomainModule extends AbstractJdbiConfigurationModule {
@Override
protected void configureJdbi() {
bindRowMapper().to(DomainMapper.class);
}
}
class DomainMapper implements RowMapper<DomainObject> {
private ColumnMapper<UUID> uuidMapper;
@Override
public void init(ConfigRegistry registry) {
this.uuidMapper = registry.get(ColumnMappers.class).findFor(UUID.class)
.orElseThrow(IllegalStateException::new);
}
@Override
public DomainObject map(ResultSet rs, StatementContext ctx) throws SQLException {
return new DomainObject(
uuidMapper.map(rs, "id", ctx),
rs.getString("name"),
rs.getString("data"),
rs.getInt("value"),
rs.getBoolean("flag"));
}
}If the DomainModule is bound within Guice, then all configured Jdbi instances will be able to map DomainObject instances without having to configure them explicitly as a row mapper.
Multiple modules extending AbstractJdbiConfigurationModule can be installed in a single injector; the resulting bindings will be aggregated.
It is not possible to install a configuration module from within the configureJdbi method of a definition module using the install() or binder().install() methods!
Definition modules are Guice private modules and anything defined within them will not be exposed to the general dependency tree. This is a limitation due to the way Guice works.
|
16.7.6. Advanced Topics
Exposing additional bindings
Each definition module that defines a Jdbi instance keeps all bindings private and exposes only the actual Jdbi object itself. This allows the installation of multiple modules where each definition is completely independent. Sometimes it is useful to attach additional objects and expose them using the same annotations. The most common use cases are data access objects.
Consider a use case where two DataSource instances exist, one annotated as Writer and the other as Reader. Both are accessing databases with the same schema, and it makes sense to have two data access objects that are identical except that they are using the different data sources (this is often referred to as the "robot legs" problem of dependency injection).
interface DatabaseAccess {
@SqlUpdate("INSERT INTO data_table ....")
int insert(...);
@SqlQuery("SELECT * FROM data_table")
Data select();
}To bind two instances of this data access object and connect each to the appropriate Jdbi instance, add the binding to the Jdbi definition module and expose it with exposeBinding(Class<?>) or exposeBinding(TypeLiteral<?>):
class DatabaseModule extends AbstractJdbiDefinitionModule {
public DatabaseModule(Class<? extends Annotation> a) {
super(a);
}
@Provides
@Singleton
DatabaseAccess createDatabaseAccess(Jdbi jdbi) {
return jdbi.onDemand(DatabaseAccess.class);
}
@Override
public void configureJdbi() {
// ... bind mappers, plugins etc. ...
exposeBinding(DatabaseAccess.class);
}
}Now install the module multiple times with different annotation classes:
Injector injector = Guice.createInjector(
// bind existing data sources
binder -> binder.bind(DataSource.class).annotatedWith(Reader.class).toInstance(...);
binder -> binder.bind(DataSource.class).annotatedWith(Writer.class).toInstance(...);
new DatabaseModule(Reader.class),
new DatabaseModule(Writer.class)
);
// fetch object directly from the injector
DatabaseAccess readerAccess = injector.getInstance(Key.get(DatabaseAccess.class, Reader.class));
DatabaseAccess writerAccess = injector.getInstance(Key.get(DatabaseAccess.class, Writer.class));Importing external bindings
The main use case of guice is code modularization and code reuse. Jdbi definition modules can pull dependencies out of the global dependency definitions and using the importBinding and importBindingLoosely methods.
importBinding requires a dependency to exist and pulls it into the definition module. The dependency must be defined using the same annotation or annotation class as the definition module uses.
This example shows how to define an external dependency (SpecialLogger, annotated with Store) in a different module and then pull it into the definition module using importBinding:
//
// This is logging code that can be located e.g. in a specific part of the code base that
// deals with all aspects of logging. The Logging module creates the binding for the special
// logger depending on the environment that the code has been deployed in.
class LoggingModule extends AbstractModule {
private final boolean production;
private final Class<? extends Annotation> annotation;
LoggingModule(boolean production, Class<? extends Annotation> annotation) {
this.production = production;
this.annotation = annotation;
}
@Override
public void configure() {
if (production) {
bind(SpecialLogger.class).annotatedWith(annotation).toInstance(new MaskingLogger());
} else {
bind(SpecialLogger.class).annotatedWith(annotation).toInstance(new DebugLogger());
}
}
}
//
// This is Jdbi code that deals with the data store. It can be located in a different part of the
// application. It requires the "SpecialLogger" dependency to be bound somewhere.
//
@Singleton
class JdbiSpecialLogging implements GuiceJdbiCustomizer {
private final SpecialLogger logger;
@Inject
JdbiSpecialLogging(SpecialLogger logger) {
this.logger = logger;
}
@Override
public void customize(Jdbi jdbi) {
jdbi.setSqlLogger(new SpecialSqlLogger(logger));
}
}
class DatabaseModule extends AbstractJdbiDefinitionModule {
public DatabaseModule(Class<? extends Annotation> a) {
super(a);
}
@Override
public void configureJdbi() {
... bind mappers, plugins etc. ...
// pull the "SpecialLogger" annotated with Store into the module scope
importBinding(SpecialLogger.class).in(Scopes.SINGLETON);
bindCustomizer().to(JdbiSpecialLogging.class);
}
}
Injector injector = Guice.createInjector(
new LoggingModule(production, Store.class),
new DatabaseModule(Store.class)
)importBinding returns a binding builder, that allows different binding styles:
class DatabaseModule extends AbstractJdbiDefinitionModule {
@Override
public void configureJdbi() {
// simplest use case, pull in Foo.class using the same annotation
importBinding(Foo.class);
// supports everything that a ScopedBindingBuilder does
importBinding(Foo.class).in(Scopes.SINGLETON);
// supports "to()" to bind interfaces to implementation
importBinding(Foo.class).to(FooImpl.class);
// supports type literals
importBinding(new TypeLiteral<Set<Foo>>() {}).to(FooSet.class);
// supports binding into the various binder methods as well
// pull SpecialCustomizer using the same annotation as the module and add it to the set of customizers
importBinding(bindCustomizer(), SpecialCustomizer.class).in(Scopes.SINGLETON);
// bind column mapper using a type literal
importBinding(bindColumnMapper(), new TypeLiteral<Map<String, Object>>() {}).to(JsonMapper.class);
}
}Static bindings require that the dependency is always defined. However, it is often desirable to have optional bindings that do not need to exist. This is supported using the importLooseBinding mechanism.
class DropwizardStoreModule extends AbstractModule {
@Store
@Provides
@Singleton
DropwizardJdbiSupport getDropwizardJdbiSupport(@Dropwizard DataSourcConfiguration configuration, @Dropwizard Environment environment) {
return new DropwizardJdbiSupport("store", configuration, environment);
}
static class DropwizardJdbiSupport implements GuiceJdbiCustomizer {
private final String name;
private final Environment environment;
private final DataSourceConfiguration<?> configuration;
DropwizardJdbiSupport(String name, DataSourceConfiguration configuration, Environment environment) {
this.name = name;
this.configuration = configuration;
this.environment = environment;
}
@Override
public void customize(final Jdbi jdbi) {
final String validationQuery = configuration.getValidationQuery();
environment.healthChecks().register(name, new JdbiHealthCheck(
environment.getHealthCheckExecutorService(),
configuration.getValidationQueryTimeout().orElse(Duration.seconds(5)),
jdbi,
Optional.of(validationQuery)));
}
}
class StoreJdbiModule extends AbstractJdbiDefinitionModule {
@Override
public void configureJdbi() {
// ... other Jdbi code bindings for the store ...
importBindingLoosely(bindCustomizer(), GuiceJdbiCustomizer.class)
.withDefault(GuiceJdbiCustomizer.NOP)
.to(DropwizardJdbiSupport.class);
}
}
// production code (running in dropwizard framework)
Injector injector = Guice.createInjector(
new DropwizardModule(), // binds @Dropwizard stuff
new DropwizardStoreModule(), // binds dropwizard support for store jdbi
new StoreDataSourceModule(), // binds @Store DataSource
new StoreJdbiModule() // Store Jdbi code
);
// test code
Injector injector = Guice.createInjector(
new StoreTestingDataSourceModule(), // testing datasource for store
new StoreJdbiModule() // store Jdbi code
);In this example there is code specific to the dropwizard framework that would not work in unit tests (that are not run within the framework). This code is only bound in the production environment using the DropwizardStoreModule and not present in testing.
The StoreJdbiModule uses importBindingLoosely to pull in the DropwizardJdbiSupport binding using the Store annotation if it exists or uses a No-Op otherwise.
importBindingLoosely allows for full decoupling of optional dependencies without having to resort to conditionals or separate testing modules.
class DatabaseModule extends AbstractJdbiDefinitionModule {
@Override
public void configureJdbi() {
// simplest use case, pull in Foo.class using the same annotation
importBindingLoosely(Foo.class);
// supports everything that a ScopedBindingBuilder does
importBindingLoosely(Foo.class).in(Scopes.SINGLETON);
// supports "to()" to bind interfaces to implementation
importBindingLoosely(Foo.class).to(FooImpl.class);
// supports default value that is used if the binding
// is not present
importBindingLoosely(Foo.class)
.withDefault(new Foo("default"));
// supports type literals
importBindingLoosely(new TypeLiteral<Set<Foo>>() {}).to(FooSet.class);
// supports binding into the various binder methods as well
// pull SpecialCustomizer using the same annotation as the module and add it to the set of customizers
importBindingLoosely(bindCustomizer(), SpecialCustomizer.class).in(Scopes.SINGLETON);
// bind column mapper using a type literal
importBindingLoosely(bindColumnMapper(), new TypeLiteral<Map<String, Object>>() {}).to(JsonMapper.class);
// full example
importBindingLoosely(bindCustomizer(), GuiceJdbiCustomizer.class)
.withDefault(GuiceJdbiCustomizer.NOP)
.to(SpecialCustomizer.class)
.asEagerSingleton();
}
}Custom element configuration modules
In larger projects, Element configuration modules help to organize the various Jdbi related elements. By default, all modules contribute their configuration to a single, global configuration that is used in all Jdbi definition modules.
Sometimes it is useful to create separate configurations that only affect a subset of Jdbi definitions. This can be done by using a custom annotation for both the Jdbi element configuration and the Jdbi definition modules:
class CustomConfigurationModule extends AbstractJdbiConfigurationModule {
CustomModule() {
super(CustomConfiguration.class); // definition modules must use this annotation explictly
}
@Override
public void configureJdbi() {
bindColumnMapper().to(CustomColumnMapper.class);
bindPlugin().to(SpecialDatabaseModule.class);
}
}
class SpecialDatabaseModule extends AbstractJdbiDefinitionModule {
SpecialDatabaseModule() {
super(
SpecialDatabase.class, // The Jdbi instance is bound using this annotation class
CustomConfiguration.class // Use an explicit configuration
);
}
@Override
public void configureJdbi() {
...
}
}The Jdbi element bound with the SpecialDatabase annotation will have the SpecialDatabaseModule loaded and can use the CustomColumnMapper.
16.8. JPA
Using the JPA plugin is a great way to trick your boss into letting you try Jdbi. "No problem boss, it already supports JPA annotations, easy-peasy!"
This plugin adds mapping support for a small subset of JPA entity annotations:
-
Entity
-
MappedSuperclass
-
Column
To use this plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-jpa</artifactId>
</dependency>Then install the plugin into the Jdbi instance:
jdbi.installPlugin(new JpaPlugin());Honestly though… just tear off the bandage and switch to Jdbi proper.
16.9. Kotlin
Kotlin support is provided by jdbi3-kotlin and jdbi3-kotlin-sqlobject modules.
Kotlin API documentation:
16.9.1. ResultSet Mapping
The jdbi3-kotlin plugin adds mapping to Kotlin data classes. It supports data classes where all fields are present in the constructor as well as classes with writable properties. Any fields not present in the constructor will be set after the constructor call. The mapper supports nullable types. It also uses default parameter values in the constructor if the parameter type is not nullable and the value absent in the result set.
To use this plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-kotlin</artifactId>
</dependency>Ensure the Kotlin compiler’s JVM target version is set to at least 11:
<kotlin.compiler.jvmTarget>11</kotlin.compiler.jvmTarget>Then install the plugin into the Jdbi instance:
jdbi.installPlugin(KotlinPlugin());The Kotlin mapper also supports @ColumnName annotation that allows to specify name for a property or parameter explicitly, as well as the @Nested annotation that allows mapping nested Kotlin objects.
Instead of using @BindBean, bindBean(), and @RegisterBeanMapper use @BindKotlin, bindKotlin(), and KotlinMapper
for qualifiers on constrictor parameters, getter, setters, and setter parameters of Kotlin class.
|
The @ColumnName annotation only applies while mapping SQL data into Java objects.
When binding object properties (e.g. with bindBean()), bind the property name (:id) rather than the column name (:user_id).
|
If you load all Jdbi plugins via Jdbi.installPlugins() this plugin will be
discovered and registered automatically. Otherwise, you can attach it using
Jdbi.installPlugin(KotlinPlugin()).
An example from the test class:
data class IdAndName(val id: Int, val name: String)
data class Thing(
@Nested val idAndName: IdAndName,
val nullable: String?,
val nullableDefaultedNull: String? = null,
val nullableDefaultedNotNull: String? = "not null",
val defaulted: String = "default value"
)
@Test
fun testFindById() {
val qry = h2Extension.sharedHandle.createQuery("select id, name from something where id = :id")
val things: List<Thing> = qry.bind("id", brian.idAndName.id).mapTo<Thing>().list()
assertEquals(1, things.size)
assertEquals(brian, things[0])
}There are two extensions to help:
-
<reified T : Any>ResultBearing.mapTo() -
<T : Any>ResultIterable<T>.useSequence(block: (Sequence<T>) → Unit)
Allowing code like:
val qry = handle.createQuery("SELECT id, name FROM something WHERE id = :id")
val things = qry.bind("id", brian.id).mapTo<Thing>.list()and for using a Sequence that is auto closed:
qryAll.mapTo<Thing>.useSequence {
it.forEach(::println)
}16.9.2. SqlObject
The jdbi3-kotlin-sqlobject plugin adds automatic parameter binding by name for Kotlin methods in SqlObjects as well as support for Kotlin default methods.
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-kotlin-sqlobject</artifactId>
</dependency>Then install the plugin into the Jdbi instance:
jdbi.installPlugin(KotlinSqlObjectPlugin());Parameter binding supports individual primitive types as well as Kotlin or
JavaBean style objects as a parameter (referenced in binding as
:paramName.propertyName). No annotations are needed.
If you load all Jdbi plugins via Jdbi.installPlugins() this plugin will be
discovered and registered automatically. Otherwise, you can attach the plugin
via: Jdbi.installPlugin(KotlinSqlObjectPlugin()).
An example from the test class:
interface ThingDao {
@SqlUpdate("insert into something (id, name) values (:something.idAndName.id, :something.idAndName.name)")
fun insert(something: Thing)
@SqlQuery("select id, name from something")
fun list(): List<Thing>
}
@BeforeEach
fun setUp() {
val dao = h2Extension.jdbi.onDemand<ThingDao>()
val brian = Thing(IdAndName(1, "Brian"), null)
val keith = Thing(IdAndName(2, "Keith"), null)
dao.insert(brian)
dao.insert(keith)
}
@Test
fun testDao() {
val dao = h2Extension.jdbi.onDemand<ThingDao>()
val rs = dao.list()
assertEquals(2, rs.size.toLong())
assertEquals(brian, rs[0])
assertEquals(keith, rs[1])
}16.9.3. Jackson JSON Processing
Jackson needs a specialized ObjectMapper instance in order to understand deserialization of Kotlin types. Make sure to configure your Jackson plugin:
import com.fasterxml.jackson.module.kotlin.jacksonObjectMapper
jdbi.getConfig(Jackson2Config::class.java).mapper = jacksonObjectMapper()16.10. Lombok
Lombok is a tool for auto-generation of mutable and immutable data classes through annotations.
@Data
public void DataClass {
private Long id;
private String name;
// autogenerates default constructor, getters, setters, equals, hashCode, and toString
}
@Value
public void ValueClass {
private long id;
private String name;
// autogenerates all-args constructor, getters, equals, hashCode, and toString
}Classes annotated with @Value are immutable, classes annotated with @Data behave like standard, mutable Java Beans.
-
Use
BeanMapperor @RegisterBeanMapper to map@Dataclasses. -
Use
ConstructorMapperor @RegisterConstructorMapper to map@Valueclasses. -
Use
bindBean()or@BindBeanto bind@Dataor@Valueclasses.
Lombok must be configured to propagate annotations from the source code into the generated classes. Since version 1.18.4, lombok
supports the lombok.copyableAnnotations setting in its config file. To support all Jdbi features, the following lines must be added:
lombok.copyableAnnotations += org.jdbi.v3.core.mapper.reflect.ColumnName
lombok.copyableAnnotations += org.jdbi.v3.core.mapper.Nested
lombok.copyableAnnotations += org.jdbi.v3.core.mapper.PropagateNull
lombok.copyableAnnotations += org.jdbi.v3.core.annotation.JdbiProperty
lombok.copyableAnnotations += org.jdbi.v3.core.mapper.reflect.JdbiConstructorAny additional annotation (such as the @HStore annotation for PostgreSQL support) can also be added:
lombok.copyableAnnotations += org.jdbi.v3.postgres.HStoreWhen using any of the Json mappers (Jackson 2, Gson 2 or Moshi ) with lombok, the @Json annotation must also be added to the lombok config file, otherwise Jdbi can not map json columns to lombok bean properties:
lombok.copyableAnnotations += org.jdbi.v3.json.Json16.11. Oracle 12
This module adds support for Oracle RETURNING DML expressions.
To use this feature, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-oracle12</artifactId>
</dependency>Then, use the OracleReturning class with an Update or PreparedBatch
to get the returned DML.
16.12. PostgreSQL
The jdbi3-postgres plugin provides enhanced integration with the PostgreSQL JDBC Driver.
To use this feature, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-postgres</artifactId>
</dependency>Then install the plugin into the Jdbi instance.
Jdbi jdbi = Jdbi.create("jdbc:postgresql://host:port/database")
.installPlugin(new PostgresPlugin());The plugin configures mappings for java.time types like Instant or Duration, InetAddress, UUID, typed enums, and hstore.
It also configures SQL array type support for int, long, float, double,
String, and UUID.
See the javadoc for an exhaustive list.
Some Postgres operators, for example the ? query operator, collide
with Jdbi or JDBC specific special characters. In such cases, you may need to
escape operators to e.g. ?? or \:.
|
16.12.1. hstore
The Postgres plugin provides an hstore to Map<String, String> column mapper
and vice versa argument factory:
Map<String, String> accountAttributes = handle
.select("SELECT attributes FROM account WHERE id = ?", userId)
.mapTo(new GenericType<Map<String, String>>() {})
.one();With @HStore qualified type:
QualifiedType<> HSTORE_MAP = QualifiedType.of(new GenericType<Map<String, String>>() {})
.with(HStore.class);
Map<String, String> caps = handle.createUpdate("UPDATE account SET attributes = :hstore")
.bindByType("hstore", mapOfStrings, HSTORE_MAP)
.execute();By default, SQL Object treats Map return types as a collection of Map.Entry
values. Use the @SingleValue annotation to override this, so that the return
type is treated as a single value instead of a collection:
public interface AccountDao {
@SqlQuery("SELECT attributes FROM account WHERE id = ?")
@SingleValue
Map<String, String> getAccountAttributes(long accountId);
}
The default variant to install the plugin adds unqualified mappings of raw Map types from and to the hstore Postgres data type. There are situations where this interferes with other mappings of maps. It is recommended to always use the variant with the @HStore qualified type.
|
To avoid binding the unqualified Argument and ColumnMapper bindings, install the plugin using the static factory method:
Jdbi jdbi = Jdbi.create("jdbc:postgresql://host:port/database")
.installPlugin(PostgresPlugin.noUnqualifiedHstoreBindings());16.12.2. @GetGeneratedKeys Annotation
In Postgres, @GetGeneratedKeys can return the entire modified row if you request generated keys without naming any columns.
public interface UserDao {
@SqlUpdate("INSERT INTO users (id, name, created_on) VALUES (nextval('user_seq'), ?, now())")
@GetGeneratedKeys
@RegisterBeanMapper(User.class)
User insert(String name);
}If a database operation modifies multiple rows (e.g. an update that will modify several rows), your method can return all the modified rows in a collection:
public interface UserDao {
@SqlUpdate("UPDATE users SET active = false WHERE id = any(?)")
@GetGeneratedKeys
@RegisterBeanMapper(User.class)
List<User> deactivateUsers(long... userIds);
}16.12.3. Large Objects
Postgres supports storing large character or binary data in separate storage from table data. Jdbi allows you to stream this data in and out of the database as part of an enclosing transaction. Operations for storing, reading, and a hook for deletions are provided. The test case serves as a simple example:
public void blobCrud(InputStream myStream) throws IOException {
h.useTransaction(th -> {
Lobject lob = th.attach(Lobject.class);
lob.insert(1, myStream);
readItBack = lob.readBlob(1);
lob.deleteLob(1);
assert lob.readBlob(1) == null;
});
}
public interface Lobject {
// CREATE TABLE lob (id int, lob oid
@SqlUpdate("INSERT INTO lob (id, lob) VALUES (:id, :blob)")
void insert(int id, InputStream blob);
@SqlQuery("SELECT lob FROM lob WHERE id = :id")
InputStream readBlob(int id);
@SqlUpdate("DELETE FROM lob WHERE id = :id RETURNING lo_unlink(lob)")
void deleteLob(int id);
}Please refer to Pg-JDBC docs for upstream driver documentation.
16.13. Spring 5
This module provides JdbiFactoryBean, a factory bean which sets up a Jdbi
singleton in a Spring 5 (or Spring Boot) application context.
To use this module, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-spring5</artifactId>
</dependency>Then configure the Jdbi factory bean in your Spring container, e.g.:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.0.xsd">
(1)
<bean id="db" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="url" value="jdbc:h2:mem:testing"/>
</bean>
(2)
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="db"/>
</bean>
<tx:annotation-driven transaction-manager="transactionManager"/>
(3)
<bean id="jdbi"
class="org.jdbi.v3.spring5.JdbiFactoryBean">
<property name="dataSource" ref="db"/>
</bean>
(4)
<bean id="service"
class="com.example.service.MyService">
<constructor-arg ref="jdbi"/>
</bean>
</beans>| 1 | The SQL data source that Jdbi will connect to. In this example we use an H2 database, but it can be any JDBC-compatible database. |
| 2 | Enable configuration of transactions via annotations. |
| 3 | Configure JdbiFactoryBean using the data source configured earlier. |
| 4 | Inject a Jdbi instance into a service class. Alternatively, use standard JSR-330 @Inject annotations on the target class instead of configuring it in your beans.xml. |
16.13.1. Installing Plugins
Plugins may be automatically installed by scanning the classpath for ServiceLoader manifests.
<bean id="jdbi" class="org.jdbi.v3.spring5.JdbiFactoryBean">
...
<property name="autoInstallPlugins" value="true"/>
</bean>Plugins may also be installed explicitly:
<bean id="jdbi" class="org.jdbi.v3.spring5.JdbiFactoryBean">
...
<property name="plugins">
<list>
<bean class="org.jdbi.v3.sqlobject.SqlObjectPlugin"/>
<bean class="org.jdbi.v3.guava.GuavaPlugin"/>
</list>
</property>
</bean>Not all plugins are automatically installable. In these situations, you can auto-install some plugins and manually install the rest:
<bean id="jdbi" class="org.jdbi.v3.spring5.JdbiFactoryBean">
...
<property name="autoInstallPlugins" value="true"/>
<property name="plugins">
<list>
<bean class="org.jdbi.v3.core.h2.H2DatabasePlugin"/>
</list>
</property>
</bean>16.13.2. Global Attributes
Global defined attributes may be configured on the factory bean:
<bean id="jdbi" class="org.jdbi.v3.spring5.JdbiFactoryBean">
<property name="dataSource" ref="db"/>
<property name="globalDefines">
<map>
<entry key="foo" value="bar"/>
</map>
</property>
</bean>16.14. SQLite
The jdbi3-sqlite plugin provides support for using the SQLite JDBC Driver with Jdbi.
The plugin configures mapping for the Java URL type which is not supported by driver.
To use this plugin, first add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-sqlite</artifactId>
</dependency>Then install the plugin into the Jdbi instance.
Jdbi jdbi = Jdbi.create("jdbc:sqlite:database")
.installPlugin(new SQLitePlugin());16.15. StringTemplate 4
This module allows you to plug in the StringTemplate 4 templating engine, in place of the standard Jdbi templating engine.
To use module plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-stringtemplate4</artifactId>
</dependency>To use StringTemplate format in SQL statements, set the template engine to StringTemplateEngine.
Defined attributes are provided to the StringTemplate engine to render the SQL:
String sortColumn = "name";
String sql = "SELECT id, name " +
"FROM account " +
"ORDER BY <if(sort)> <sortBy>, <endif> id";
List<Account> accounts = handle
.createQuery(sql)
.setTemplateEngine(new StringTemplateEngine())
.define("sort", true)
.define("sortBy", sortColumn)
.mapTo(Account.class)
.list();Since StringTemplate by default uses the < character to mark ST expressions,
you might need to escape some SQL:
String datePredicateSql = "<if(datePredicate)> <dateColumn> \\< :dateFilter <endif>";Alternatively, SQL templates can be loaded from StringTemplate group files on the classpath:
group AccountDao;
selectAll(sort,sortBy) ::= <<
SELECT id, name
FROM account
ORDER BY <if(sort)> <sortBy>, <endif> id
>>ST template = StringTemplateSqlLocator.findStringTemplate(
"com/foo/AccountDao.sql.stg", "selectAll");
String sql = template.add("sort", true)
.add("sortBy", sortColumn)
.render();In SQL Objects, the @UseStringTemplateEngine annotation sets the
statement locator, similar to first example above.
package com.foo;
public interface AccountDao {
@SqlQuery("SELECT id, name " +
"FROM account " +
"ORDER BY <if(sort)> <sortBy>, <endif> id")
@UseStringTemplateEngine
List<Account> selectAll(@Define boolean sort,
@Define String sortBy);
}Alternatively, the @UseStringTemplateSqlLocator annotation sets the statement
locator, and loads SQL from a StringTemplate group file on the classpath:
package com.foo;
public interface AccountDao {
@SqlQuery
@UseStringTemplateSqlLocator
List<Account> selectAll(@Define boolean sort,
@Define String sortBy);
}In this example, since the fully qualified class name is com.foo.AccountDao,
SQL will be loaded from the file com/foo/AccountDao.sql.stg on the
classpath.
By default, the template in the group with the same name as the method will be
used. This can be overridden on the @Sql___ annotation:
package com.foo;
public interface AccountDao {
@SqlQuery("listSorted")
@UseStringTemplateSqlLocator
List<Account> selectAll(@Define boolean sort,
@Define String sortBy);
}In this example, the SQL template will still be loaded from the file
com/foo/AccountDao.sql.stg on the classpath, however the listSorted
template will be used, regardless of the method name.
There are some options for StringTemplateEngine on the StringTemplates configuration class, like whether missing attributes are considered an error or not.
16.16. Vavr
The Vavr Plugin offers deep integration of Jdbi with the Vavr functional library:
-
Supports argument resolution of sever Vavr Value types such as
Option<T>,Either<L, T>,Lazy<T>,Try<T>andValidation<T>. Given that for the wrapped typeTa Mapper is registered. -
Return Vavr collection types from queries. Supported are
Seq<T>,Set<T>,Map<K, T>andMultimap<K, T>as well as all subtypes thereof. It is possible to collect into aTraversable<T>, in this case a List<T> will be returned. For all interface types a sensible default implementation will be used (e.q. List<T> forSeq<T>). FurthermoreMultimap<K, T>s are backed by aSeq<T>as default value container. -
Columns can be mapped into Vavr’s
Option<T>type. -
Tuple projections for Jdbi! Yey! Vavr offers Tuples up to a maximum arity of 8. you can map your query results e.g. to
Tuple3<Integer, String, Long>. If you select more columns than the arity of the projection the columns up to that index will be used.
To use the plugin, add a Maven dependency:
<dependency>
<groupId>org.jdbi</groupId>
<artifactId>jdbi3-vavr</artifactId>
</dependency>| Vavr introduced binary incompatibilities between 0.10.x and 1.0.0-alpha. The Jdbi plugin only supports 0.9.x and 0.10.x and requires recompilation for vavr 1.0.0. |
jdbi.installPlugin(new VavrPlugin());Here are some usage examples of the features listed above:
String query = "SELECT * FROM users WHERE :name is null or name = :name";
Option<String> param = Option.of("eric");
// will fetch first user with given name or first user with any name (Option.none)
return handle
.createQuery(query)
.bind("name", param)
.mapToBean(User.class)
.findFirst();where param may be one of Option<T>, Either<L, T>, Lazy<T>, Try<T>
or Validation<T>. Note that in the case of these types, the nested value must
be 'present' otherwise a null value is used (e.g. for Either.Left or
Validation.Invalid).
handle.createQuery("SELECT name FROM users")
.collectInto(new GenericType<Seq<String>>() {});This works for all the collection types supported. For the nested value row and column mappers already installed in Jdbi will be used. Therefore, the following would work and can make sense if the column is nullable:
handle.createQuery("SELECT middle_name FROM users") // nulls incoming!
.collectInto(new GenericType<Seq<Option<String>>>() {});The plugin will obey configured key and value columns for Map<K, T>
and Multimap<K, T> return types. In the next example we will key users
by their name, which is not necessarily unique.
Multimap<String, User> usersByName = handle
.createQuery("SELECT * FROM users")
.setMapKeyColumn("name")
.collectInto(new GenericType<Multimap<String, User>>() {});Last but not least we can now project simple queries to Vavr tuples like that:
// given a 'tuples' table with t1 int, t2 varchar, t3 varchar, ...
List<Tuple3<Integer, String, String>> tupleProjection = handle
.createQuery("SELECT t1, t2, t3 FROM tuples")
.mapTo(new GenericType<Tuple3<Integer, String, String>>() {})
.list();You can also project complex types into a tuple as long as a row mapper is registered.
// given that there are row mappers registered for both complex types
Tuple2<City, Address> tupleProjection = handle
.createQuery("SELECT cityname, zipcode, street, housenumber FROM " +
"addresses WHERE user_id = 1")
.mapTo(new GenericType<Tuple2<City, Address>>() {})
.one();If you want to mix complex types and simple ones we also got you covered.
Using the TupleMappers class you can configure your projections.(In fact,
you have to - read below!)
handle.configure(TupleMappers.class, c -> c.setColumn(2, "street").setColumn(3, "housenumber"));
Tuple3<City, String, Integer> result = handle
.createQuery("SELECT cityname, zipcode, street, housenumber " +
"FROM addresses WHERE user_id = 1")
.mapTo(new GenericType<Tuple3<City, String, Integer>>() {})
.one();Bear in mind:
-
The configuration of the columns is 1-based, since they reflect the tuples' values (which you would query by e.g.
._1). -
Tuples are always mapped fully column-wise or fully via row mappers. If you want to mix row-mapped types and single-column mappings the
TupleMappersmust be configured properly i.e. all non row-mapped tuple indices must be provided with a column configuration!
17. Cookbook
This section includes examples of various things you might like to do with Jdbi.
17.1. Simple Dependency Injection
Jdbi tries to be independent of using a dependency injection framework, but it’s straightforward to integrate yours. Just do field injection on a simple custom config type:
class InjectedDependencies implements JdbiConfig<InjectedDependencies> {
@Inject
SomeDependency dep;
public InjectedDependencies() {}
@Override
public InjectedDependencies createCopy() {
return this; // effectively immutable
}
}
Jdbi jdbi = Jdbi.create(myDataSource);
myIoC.inject(jdbi.getConfig(InjectedDependencies.class));
// Then, in any component that needs to access it:
getHandle().getConfig(InjectedDependencies.class).dep17.2. LIKE clauses with Parameters
Since JDBC (and therefore Jdbi) does not allow binding parameters into the middle of string literals,
you cannot interpolate bindings into LIKE clauses (LIKE '%:param%').
Incorrect usage:
handle.createQuery("SELECT name FROM things WHERE name like '%:search%'")
.bind("search", "foo")
.mapTo(String.class)
.list()This query would try to select where name like '%:search%' literally, without binding any arguments.
This is because JDBC drivers will not bind arguments inside string literals.
It never gets that far, though — this query will throw an exception, because we don’t allow unused argument bindings by default.
The solution is to use SQL string concatenation:
handle.createQuery("SELECT name FROM things WHERE name like '%' || :search || '%'")
.bind("search", "foo")
.mapTo(String.class)
.list()Now, search can be properly bound as a parameter to the statement, and it all works as desired.
| Check the string concatenation syntax of your database before doing this. |
18. The Extension Framework
The Jdbi core provides a rich, programmatic interface for database operations. It is possible to extend this core by writing extensions that plug into the Jdbi core framework and provide new functionality.
The Extension framework is generic and supports any type of extension that can be registered with the Jdbi core.
Jdbi provides the SQLObject plugin, which offers a declarative API by placing annotations on interface methods.
18.1. Using Jdbi extensions
Extension types are usually java interface classes. Any interface can be an extension type.
Jdbi offers multiple ways to obtain an extension type implementation:
-
Calling either Jdbi#withExtension() or Jdbi#useExtension() methods with an extension type will pass an extension type implementation to a callback that contains user code.
-
The Handle#attach() attaches an extension type implementation directly to an existing Handle object.
-
Finally, the Jdbi#onDemand() method creates an on-demand implementation of an extension type that is not limited to a callback.
This is an extension type for the SQL Object extension which uses annotations to identify functionality:
interface SomethingDao {
@SqlUpdate("INSERT INTO something (id, name) VALUES (:s.id, :s.name)")
int insert(@BindBean("s") Something s);
@SqlQuery("SELECT id, name FROM something WHERE id = ?")
Optional<Something> findSomething(int id);
}If any of the SQL method annotations (@SqlBatch, @SqlCall, @SqlQuery, @SqlScript and @SqlUpdate) is present on either the extension type itself or any extension type method, the SQL Object extension will be used.
The Jdbi#withExtension() and Jdbi#useExtension() methods are used to access SQLObject functionality:
jdbi.useExtension(SomethingDao.class, dao -> {
dao.insert(new Something(1, "apple"));
});
Optional<Something> result = jdbi.withExtension(SomethingDao.class, dao -> dao.findSomething(1));If a handle has already been created, an extension type can be directly attached with the Handle#attach() method:
SomethingDao dao = handle.attach(SomethingDao.class);
Optional<Something> result = dao.findSomething(1);The Jdbi#withExtension(), Jdbi#useExtension() and Handle#attach() methods are the most common way to use extension type implementations.
18.1.1. On-demand extensions
An extension type implementation can be acquired by calling the Jdbi#onDemand() method which returns an implementation of the extension type that will transparently create a new handle instance when a method on the extension type is called.
This is an example for an on-demand extension:
SomethingDao dao = jdbi.onDemand(SomethingDao.class);
dao.insert(new Something(1, "apple"));
Optional<Something> result = dao.findSomething(1);| The Jdbi#onDemand() uses a Java proxy object to provide the on-demand handle object. Java proxies only support Java interface classes as extension types and may not be compatible with GraalVM when creating native code. |
18.1.2. Handle lifecycle for extensions
The difference between the methods to acquire an extension type implementation is the handle (and database connection) lifecycle:
-
Jdbi#withExtension() and Jdbi#useExtension() provides a managed handle object when the callback is entered and reuses it for any extension type method call as long as the code does not return from the callback.
-
The Handle#attach() does not manage the handle at all. Any extension type method call will use the handle that the object was attached to and be part of its lifecycle.
-
The Jdbi#onDemand() provides a managed handle object for every extension type method call. When the method call returns, the handle is closed.
18.2. How an extension works
Any interface class can be an extension type. There is nothing special to an extension type unless an extension requires some specific information (e.g. annotations present or specific naming).
Extensions should document which information is needed for the extension framework to determine that a specific interface class represents an extension type that they accept.
The extension type creation methods (Jdbi#withExtension(), Jdbi#useExtension(), Handle#attach() and Jdbi#onDemand()) all take the extension type as a parameter and provide an implementation either to the caller or within a callback object.
The extension framework selects an ExtensionFactory to handle the extension type and create an implementation. Extension factories must be registered ahead of time with the Jdbi core using the Extensions#register() method.
The extension factory then creates an ExtensionMetadata object that contains information about each method on the extension type:
-
Which ExtensionHandler to invoke for each method
-
All ExtensionHandlerCustomizer instances that change the behavior of the extension handler
-
Per extension type and per extension type method specific ConfigCustomizer instances to apply when an extension handler is invoked
Extension metadata is created once for each extension type and then reused.
Jdbi usually returns a Java proxy object to user code. Calling a method on that proxy will invoke per-method extension handlers. For each extension handler, objects specific to the invocation (Handle, configuration) are managed separately .
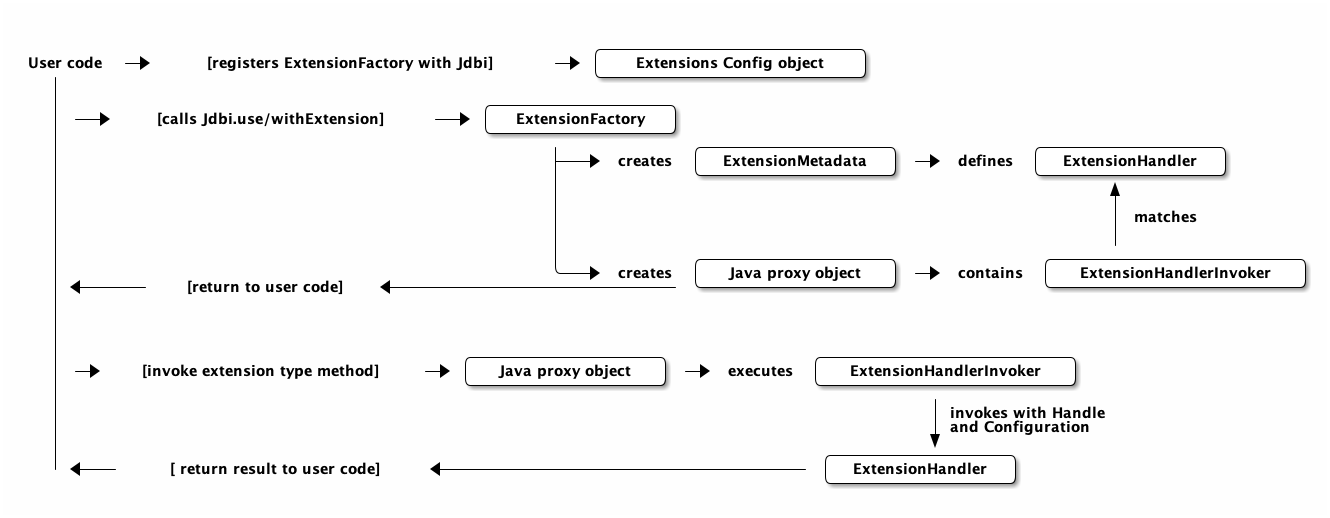
ExtensionHandler, ExtensionHandlerCustomizer and ConfigCustomizer are the three main extension framework objects to implement:
-
An ExtensionHandler object is created by an ExtensionHandlerFactory, which can be registered either globally (with the Extensions configuration) and then applied to all extensions types, or directly with an extension factory. It is also possible to specify extension handlers through annotations.
-
ExtensionHandlerCustomizer objects can modify the behavior of an extension handler. They are registered globally or provided by an extension factory. They can also be specified through annotations.
-
ConfigCustomizer objects are created by a ConfigCustomizerFactory and modify the configuration that is used when an extension handler is executed. Factory instances are registered globally or with an extension factory. Config customization can also be specified through annotations.
18.3. Extension framework SDK
| This chapter is intended for developers who want to write a new extension for Jdbi and need to understand the Extension framework details. This chapter is only relevant if you plan to write an extension or implement specific extension objects. |
This chapter lists all the classes that make up the extension framework, their function and how to use them when writing a new extension. Not all pieces are needed for every extension.
18.3.1. Extension configuration
The Extensions class is the configuration object for the extension framework. It contains a registry for extension factories and global extension objects (ExtensionHandlerFactory, ExtensionHandlerCustomizer and ConfigCustomizerFactory).
Any extension object registered here will be applied to all extension types, independent of the extension factory which is ultimately chosen to process an extension type.
By default, the following extension objects are globally registered and can not be removed. These are always processed last (after all user registered extension objects):
-
An extension handler factory for the @UseExtensionHandler annotation.
-
An extension handler customizer for the @UseExtensionHandlerCustomizer annotation.
-
A config customizer factory for the @UseExtensionConfigurer annotation.
| Order matters with extension objects! For each extension object, the extension specific instances are applied first, then the globally registered ones. |
18.3.2. The Extension factory
Extension factories are the core piece for any extension. An ExtensionFactory object can provide all the specific pieces that make up the extension functionality or delegate to annotations.
The only method that must be implemented in this interface is
ExtensionFactory#accepts(). If this method returns true, then the given
extension type is handled by this factory. E.g. the SQL Object factory accepts any interface that has at least
one SQL annotation on the class itself or a method.
| Even though it is possible to implement all the functions of an extension with annotations, there still needs to be an extension factory that accepts the extension type. Without such a factory, the extension framework will throw a NoSuchExtensionException. |
Any extension factory can provide specific extension objects (by returning instances of ExtensionHandlerFactory, ExtensionHandlerCustomizer and ConfigCustomizerFactory) which are only applied when the factory has accepted an extension type. The extension factory provides the ExtensionFactory#getExtensionHandlerFactories(), ExtensionFactory#getExtensionHandlerCustomizers() and ExtensionFactory#getConfigCustomizerFactories() getters that a factory can implement. By default, each returns an empty collection.
Java Object methods
When the extension framework returns an implementation of an extension type, it usually returns a Java proxy object which will invoke an extension handler for every method on the extension type.
In addition to the methods defined by the extension type, the following methods also invoke extension handlers:
-
Object#toString() returns "Jdbi extension proxy for <extension type>"
-
Object#equals() and Object#hashCode() implementations that ensure that each instance is only equal to itself.
-
Object#finalize() has no effect.
All methods except finalize() can be overridden by the extension type (e.g. through an interface default method).
Non-virtual factories
Normally, a factory will use extension handlers to provide functionality when an extension type method is called and a Java proxy object is returned as an implementation of the extension type. This is a virtual factory (because there is no actual object implementing the interface). Extension factories are by default virtual factories.
The SQL Object extension is an example of a virtual factory because it never provides an implementation for extension types but dispatches any method calls to a specific handler to execute SQL operations.
The extension framework also supports non-virtual factories. These factories produce a backing object that implements the extension type. A non-virtual factory will still return a proxy object to the caller but calling any method on the proxy object may call the corresponding method on the backing object through a special extension handler.
This is an example of a non-virtual factory that provides an implementation for a specific extension type:
public static class NonVirtualExtensionFactory implements ExtensionFactory {
@Override
public Set<FactoryFlag> getFactoryFlags() {
return EnumSet.of(NON_VIRTUAL_FACTORY); (1)
}
@Override
public boolean accepts(Class<?> extensionType) {
return extensionType == NonVirtualDao.class;
}
@Override
public <E> E attach(Class<E> extensionType, HandleSupplier handleSupplier) {
return (E) new NonVirtualDaoImpl(handleSupplier); (2)
}
}| 1 | An extension factory declares itself non-virtual by returning the
NON_VIRTUAL_FACTORY flag on the
ExtensionFactory#getFactoryFlags() method. |
| 2 | The extension framework calls the ExtensionFactory#attach() method with the current extension type and a handle supplier. The factory is expected to return an instance of the extension type. Methods on the instance will be wrapped in extension handlers and a proxy object is returned to the caller. |
Extensions without Java proxy objects
A drawback of the standard extension factories is that returning a Java proxy object limits factory functionality and is incompatible with some use cases (e.g. using GraalVM for native compilation).
A factory can return the DONT_USE_PROXY flag on the
ExtensionFactory#getFactoryFlags() method to signal that the extension framework should
return the backing object as-is.
This is an example of a factory that supports abstract classes in addition to interfaces. Abstract classes are incompatible with java proxies, so the factory
must use the DONT_USE_PROXY flag:
abstract static class AbstractDao {
public abstract Optional<Something> findSomething(int id);
Something findFirstSomething() {
return findSomething(1).orElseGet(Assertions::fail);
}
}
public static class DontUseProxyExtensionFactory implements ExtensionFactory {
@Override
public Set<FactoryFlag> getFactoryFlags() {
return EnumSet.of(DONT_USE_PROXY); (1)
}
@Override
public boolean accepts(Class<?> extensionType) {
return extensionType == AbstractDao.class;
}
@Override
public <E> E attach(Class<E> extensionType, HandleSupplier handleSupplier) {
return extensionType.cast(new DaoImpl(handleSupplier)); (2)
}
}| 1 | An extension factory declares that it does not want to use the proxy mechanism by returning the
DONT_USE_PROXY flag from the
ExtensionFactory#getFactoryFlags() method. Using this flag bypasses all the extension
framework proxy mechanism and calls the
ExtensionFactory#attach() method
immediately. |
| 2 | The extension factory creates an instance that must be compatible with the extension type. It can provide the current extension type and a handle supplier if needed. Unlike a non-virtual factory, this instance is returned as-is to the caller. Neither proxy object nor extension handlers are created. |
Jdbi provides an annotation processor that creates java implementations of extension types. In addition, it provides an extension factory which does not use proxy objects and returns these as extension type implementations. Calling a method on the extension type will invoke the methods on the generated classes directly.
18.3.3. Extension handlers and their factories
ExtensionHandler objects are the main place for extension functionality. Each method on an extension type is mapped to an extension handler. Extension handlers are executed by calling the ExtensionHandler#invoke() method.
This is an example of an extension handler that provides a value whenever a method on the extension type is called:
public static class TestExtensionHandler implements ExtensionHandler {
@Override
public Object invoke(HandleSupplier handleSupplier, Object target, Object... args) {
return new Something((int) args[0], (String) args[1]); (1)
}
}| 1 | Invoking this handler returns a Something instance. |
Extension handlers are not shared, so every extension type method maps onto a separate instance. The ExtensionHandlerFactory interface provides the ExtensionHandlerFactory#accepts() method which is called for each method that needs to be mapped. If a factory accepts a method, the ExtensionHandlerFactory#createExtensionHandler() method is called, which should return an extension handler instance.
This is an example for an extension handler factory that returns an extension handler for methods named getSomething:
public static class TestExtensionHandlerFactory implements ExtensionHandlerFactory {
@Override
public boolean accepts(Class<?> extensionType, Method method) {
return method.getName().equals("getSomething"); (1)
}
@Override
public Optional<ExtensionHandler> createExtensionHandler(Class<?> extensionType, Method method) {
return Optional.of(new TestExtensionHandler()); (2)
}
}
interface ExtensionType {
Something getSomething(int id, String name);
}| 1 | The extension handler factory tests that the method has the right name. |
| 2 | If the factory accepts the method, it returns a new instance of the extension handler shown above. |
The ExtensionHandlerFactory#createExtensionHandler() method returns an Optional<ExtensionHandler> object for backwards compatibility reasons. While it is legal for a factory to accept a method on an extension type and then return an Optional.empty() object, it is discouraged in new code.
| The extension framework provides extension handlers for interface default methods and synthetic methods. |
An extension handler for a specific extension type can be either registered globally by adding a factory using the Extensions#registerHandlerFactory() method, or it can be returned on the ExtensionFactory#getExtensionHandlerFactories() method of the extension factory for the extension type. It can also be configured through an annotation.
This is the extension factory for the ExtensionType extension type defined above:
public static class TestExtensionFactory implements ExtensionFactory {
@Override
public boolean accepts(Class<?> extensionType) {
return extensionType == ExtensionType.class; (1)
}
@Override
public Collection<ExtensionHandlerFactory> getExtensionHandlerFactories(ConfigRegistry config) {
return Collections.singleton(new TestExtensionHandlerFactory()); (2)
}
}| 1 | The factory will accept the ExtensionType extension type. |
| 2 | When processing the type, the TestExtensionHandlerFactory shown above will be used when creating the extension handlers. |
18.3.4. Extension handler customizers
ExtensionHandlerCustomizer objects can modify extension handler execution. They are either registered globally with the Extensions#registerHandlerCustomizer() and will augment any extension handler, or they can be provided by an extension factory by implementing the ExtensionFactory#getConfigCustomizerFactories() method.
Here is an example for an extension handler customizer that logs every method handler invocation. It gets registered as a global extension handler customizer with the Extensions configuration object and will then log every method invocation on an extension type.
jdbi.configure(Extensions.class, e ->
e.registerHandlerCustomizer(new LoggingExtensionHandlerCustomizer())); (1)
static class LoggingExtensionHandlerCustomizer implements ExtensionHandlerCustomizer {
@Override
public ExtensionHandler customize(ExtensionHandler handler, Class<?> extensionType, Method method) {
return (handleSupplier, target, args) -> {
LOG.info(format("Entering %s on %s", method, extensionType.getSimpleName()));
try {
return handler.invoke(handleSupplier, target, args);
} finally {
LOG.info(format("Leaving %s on %s", method, extensionType.getSimpleName()));
}
};
}
}| 1 | Register as a global ExtensionHandlerCustomizer instance to log every method invocation. |
| This is example code. Jdbi actually offers better logging facilities with SqlLogger and the SqlStatements#setSqlLogger() method. |
ExtensionHandlerCustomizer instances usually wrap or replace an existing extension handler. They must be stateless and can only modify or operate on the ExtensionHandler object that was passed into the ExtensionHandlerCustomizer#customize() method.
18.3.5. Config customizers and their factories
ConfigCustomizer instances modify the configuration registry object which is used when an extension type method is invoked. This configuration object is passed to all extension handler customizers and the extension handler itself.
Config customizer instances are created by ConfigCustomizerFactory instances which decide whether to provide a config customizer for every method on an extension type by implementing the ConfigCustomizerFactory#forExtensionType() method, or it can implement ConfigCustomizerFactory#forExtensionMethod() for per-method selection.
This is an example for a global configuration customizer that registers a specific row mapper for all methods on every extension type.
jdbi.configure(Extensions.class, e ->
e.registerConfigCustomizerFactory(new SomethingMapperConfigCustomizerFactory())); (1)
static class SomethingMapperConfigCustomizerFactory implements ConfigCustomizerFactory {
@Override
public Collection<ConfigCustomizer> forExtensionType(Class<?> extensionType) {
return Collections.singleton(
config -> config.get(RowMappers.class).register(new SomethingMapper()) (2)
);
}
}| 1 | Register a global config customizer. It will be applied to all extension types. |
| 2 | Register the SomethingMapper to the every extension handler for every extension type. |
18.4. Annotations
A Jdbi extension like the SQL Object extension uses annotations on the extension types. It is possible to implement a large part of the functionality directly as annotation related objects without having to provide extension objects through an extension factory.
The extension framework offers meta-annotations to configure ExtensionHandler and ExtensionHandlerCustomizer instances directly and another meta-annotation to define ExtensionConfigurer instances which allows configuration modification similar to ConfigCustomizer).
Meta-annotations are used to annotate other annotation classes for processing by the extension framework.
18.4.1. Extension handler annotation
The @UseExtensionHandler meta-annotation marks any other annotation as defining an extension handler.
These annotations must be placed on a method in an extension type, therefore annotations that are marked with the meta-annotation should use the @Target({ElementType.METHOD}) annotation to limit their scope.
The extension framework processes all annotations that use this meta-annotation. It will instantiate the extension handler by locating
-
a constructor that takes both the extension type and a method object
-
a constructor that takes only the extension type
-
a no-argument constructor
If none of those can be found, an exception will be thrown.
When using this meta-annotation, the UseExtensionHandler#id() method must return an id value that is specific for the extension factory that should process the annotation. This allows multiple extensions that use annotations to co-exist.
This is an example of an annotation that provides the handler for the getSomething method on an extension type:
jdbi.configure(Extensions.class, extensions -> (1)
extensions.register(extensionType ->
Stream.of(extensionType.getMethods())
.anyMatch(method ->
Stream.of(method.getAnnotations())
.map(annotation -> annotation.annotationType()
.getAnnotation(UseExtensionHandler.class)) (2)
.anyMatch(a -> a != null && "test".equals(a.id())) (3)
)));
interface ExtensionType {
@SomethingAnnotation (4)
Something getSomething(int id, String name);
}
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD}) (5)
@UseExtensionHandler(id = "test", (6)
value = SomethingExtensionHandler.class) (7)
@interface SomethingAnnotation {}
public static class SomethingExtensionHandler implements ExtensionHandler {
@Override
public Object invoke(HandleSupplier handleSupplier, Object target, Object... args) {
return new Something((int) args[0], (String) args[1]);
}
}| 1 | An extension factory that implements only the ExtensionFactory#accepts() method can be written as a lambda. |
| 2 | The factory accepts this extension type if it has at least one method that is annotated with the @UseExtensionHandler meta-annotation. |
| 3 | Ensure that the annotation uses the test id value. |
| 4 | The @SomethingAnnotation provides the extension handler. Any method with this annotation will use the same extension handler. |
| 5 | The custom annotation targets only methods. |
| 6 | The test id value ensures that the registered factory will accept the extension type. Any extension type must be accepted by a factory, otherwise the
extension framework will reject the extension type. |
| 7 | The annotation provides the extension handler class. An instance of this class is created by the extension framework directly without an extension handler factory. |
| Even though multiple extensions can can be used at the same time, they can not share an extension type. Every extension type will only get extension handlers associated with a single factory. It is not possible to have an extension type where methods are processed by extension handlers that are annotated with annotations that use different id values. Any extension handler must be provided either by annotations that match the id value of the ExtensionFactory or an extension handler factory. |
All SQL method annotations in the Jdbi SQL Object extension (@SqlBatch, @SqlCall, @SqlQuery, @SqlScript and @SqlUpdate) are marked with this meta-annotation.
18.4.2. Extension handler customizer annotation
The @UseExtensionHandlerCustomizer meta-annotation marks any other annotation as defining an extension handler customizer.
An example in the SQL object extension is the @Transaction annotation which allows wrapping multiple SQL operations into a database transaction.
Extension handler customizers either apply to all methods in an extension type by adding an annotation to the extension type, or to specific methods by adding the annotation to a method:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE}) (1)
@UseExtensionHandlerCustomizer(
value = LoggingExtensionHandlerCustomizer.class)
@interface LogThis {}
interface MethodExtensionType {
@LogThis (2)
@SomethingAnnotation
Something getSomething(int id, String name);
}
@LogThis (3)
interface InstanceExtensionType {
@SomethingAnnotation
Something getSomething(int id, String name);
}| 1 | An annotation that uses the @UseExtensionHandlerCustomizer annotation can be placed on a method or the extension type itself. |
| 2 | The extension handler customizer is only applied to an annotated method. |
| 3 | The extension handler customizer is applied to all methods on the extension type. |
The extension framework processes all annotations that use this meta-annotation. It will instantiate the extension handler customizer by locating
-
a constructor that takes both the extension type and a method object
-
a constructor that takes only the extension type
-
a no-argument constructor
If none of those can be found, an exception will be thrown.
This is an example for an annotation that provides a handler customizer which logs method entry and exit for any extension handler:
public static class LoggingExtensionHandlerCustomizer implements ExtensionHandlerCustomizer {
@Override
public ExtensionHandler customize(ExtensionHandler handler, Class<?> extensionType, Method method) {
return (handleSupplier, target, args) -> {
LOG.info(format("Entering %s on %s", method, extensionType.getSimpleName()));
try {
return handler.invoke(handleSupplier, target, args);
} finally {
LOG.info(format("Leaving %s on %s", method, extensionType.getSimpleName()));
}
};
}
}Extension handler customizer objects are not tied to a specific extension factory. This is an example where SQL Object method annotations are used with the custom logging annotation:
interface SomethingDao {
@SqlUpdate("INSERT INTO something (id, name) VALUES (:s.id, :s.name)")
int insert(@BindBean("s") Something s);
@SqlQuery("SELECT id, name FROM something WHERE id = ?")
@LogThis
Optional<Something> findSomething(int id);
}Specifying extension handler customization order
When multiple extension customizers are used on the same extension type method, the order in which they are applied is undefined. If a specific order is required (e.g. because one customization depends on another), the @ExtensionHandlerCustomizationOrder annotation may be used to enforce a specific order.
Listing the annotation classes orders the extension customizers from outermost to innermost (outermost is called first). Any unlisted annotation will still be applied but its position is undefined. It is recommended to list all applicable annotation classes when specifying the order.
interface OrderedCustomizers {
@Bar
@Foo
@ExtensionHandlerCustomizationOrder({Foo.class, Bar.class}) (1)
void execute();
}| 1 | The annotation ensures that the Foo extension customizer is called first, then the Bar extension customizer. Otherwise, the order is undefined. |
18.4.3. Extension handler configurer annotation
The @UseExtensionConfigurer meta-annotation marks any other annotation as defining an extension configurer.
Similar to extension handler customizers, configurers either apply to all methods in an extension type by adding an annotation to the extension type, or to specific methods by adding the annotation to a method.
The meta-annotation provides an implementation of the ExtensionConfigurer.
-
the ExtensionConfigurer#configureForType() is called if the anntation is placed on the extension type
-
method provides and ExtensionConfigurer#configureForMethod() is called when the annotation is placed on an extension type method
These methods are the equivalent of ConfigCustomizerFactory#forExtensionType() and ConfigCustomizerFactory#forExtensionMethod().
The extension framework processes all annotations that use this meta-annotation.
It will instantiate the extension configurer by locating
-
a constructor that takes the annotation, the extension type, and a method object
-
a constructor that takes the annotation and the extension type
-
a constructor that takes the annotation only
-
a no-argument constructor
If none can be found, an exception will be thrown.
This is an example of an extension configurer annotation that adds a specific row mapper:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
@UseExtensionConfigurer(value = SomethingMapperExtensionConfigurer.class) (1)
@interface RegisterSomethingMapper {}
interface SomethingDao {
@SqlUpdate("INSERT INTO something (id, name) VALUES (:s.id, :s.name)")
int insert(@BindBean("s") Something s);
@SqlQuery("SELECT id, name FROM something WHERE id = ?")
@RegisterSomethingMapper (2)
Optional<Something> findSomething(int id);
}
public static class SomethingMapperExtensionConfigurer extends SimpleExtensionConfigurer { (3)
@Override
public void configure(ConfigRegistry config, Annotation annotation, Class<?> extensionType) {
config.get(RowMappers.class).register(new SomethingMapper());
}
}| 1 | define the extension configurer class in the annotation |
| 2 | add the custom annotation to a method in a SQL Object extension type |
| 3 | The implementation extends SimpleExtensionConfigurer as it should behave the same when used on an extension type or an extension type method. |
Similar to extension handler customizer objects, extension configurers are also not tied to a specific extension factory. In the example above, a custom extension configurer is used in combination with the SQL Object extension annotations.
| If an extension configurer should behave the same way independent of its position, the implementation should extend SimpleExtensionConfigurer and implement the SimpleExtensionConfigurer#configure() method. |
The SQL Object extension implements all per-method and per-class registration of specific objects (e.g. @RegisterColumnMapper or @RegisterRowMapper) through extension configurer objects which in turn create config customizer instances.
18.5. Extension metadata
| Interacting directly with the ExtensionMetadata and ExtensionHandlerInvoker is an advanced use case when writing specific extension code. For most extensions, all metadata interactions are handled by the framework and don’t require anything special. |
For every extension type that is processed by the framework, an ExtensionMetadata object is created. It collects all the information that is required to create the java proxy object:
-
extension handlers for each extension type method including optional extension handler customizers.
-
instance config customizers which are applied to every method
-
method specific config customizers
Extension metadata is created using a builder when an extension type is processed for the first time. It is possible for an ExtensionFactory to participate in the metadata creation. E.g. the SQL Object extension uses this to add extension handlers for the SqlObject interface methods.
If an extension factory wants to participate in the metadata creation, it needs to implement the ExtensionFactory#buildExtensionMetadata() method which is called with the extension metadata builder right before the actual metadata object is created. See the ExtensionMetadata.Builder documentation for all available methods.
Metadata for an extension type can be retrieved from the Extensions configuration object by calling the Extensions#findMetadata().
A metadata object can create ExtensionHandlerInvoker instances for all methods on the extension type that is represents. An extension handler invoker binds the actual extension handler instance to a specific configuration object (and the config customizers applied to that configuration object).
The main use case is within an extension type implementation class as it requires a HandlerSupplier instance, which is only available through the ExtensionFactory#attach() method. By creating extension handler invokers and metadata manually, an implementation can sidestep all the proxy logic and directly wire up method invocation or redirect invocations between methods. The jdbi SQL object generator uses this mechanism to create implementation classes that do not need the java proxy logic (which is problematic with GraalVM).
This is an example of creating and calling an extension handler invoker directly:
@Test
public void testIdOne() {
Something idOne = jdbi.withExtension(ExtensionType.class, ExtensionType::getIdOne);
assertThat(idOne).isEqualTo(new Something(1, "apple"));
}
interface ExtensionType {
Something getSomething(int id, String name);
Something getIdOne(); (1)
}
public static class TestExtensionFactory implements ExtensionFactory {
@Override
public boolean accepts(Class<?> extensionType) {
return extensionType == ExtensionType.class;
}
@Override
public <E> E attach(Class<E> extensionType, HandleSupplier handleSupplier) {
ExtensionMetadata extensionMetadata = handleSupplier.getConfig() (2)
.get(Extensions.class).findMetadata(extensionType, this);
return extensionType.cast(new ExtensionTypeImpl(extensionMetadata, handleSupplier)); (3)
}
@Override
public Set<FactoryFlag> getFactoryFlags() {
return EnumSet.of(DONT_USE_PROXY); (4)
}
@Override
public Collection<ExtensionHandlerFactory> getExtensionHandlerFactories(ConfigRegistry config) {
return Collections.singleton(new TestExtensionHandlerFactory()); (5)
}
}
public static class TestExtensionHandlerFactory implements ExtensionHandlerFactory {
@Override
public boolean accepts(Class<?> extensionType, Method method) {
return method.getName().equals("getSomething"); (6)
}
@Override
public Optional<ExtensionHandler> createExtensionHandler(Class<?> extensionType, Method method) {
return Optional.of((handleSupplier, target, args) -> new Something((int) args[0], (String) args[1]));
}
}
static class ExtensionTypeImpl implements ExtensionType {
private final ExtensionHandlerInvoker getSomethingInvoker;
private ExtensionTypeImpl(ExtensionMetadata extensionMetadata, HandleSupplier handleSupplier) {
ConfigRegistry config = handleSupplier.getConfig();
this.getSomethingInvoker = extensionMetadata.createExtensionHandlerInvoker(this,
JdbiClassUtils.methodLookup(ExtensionType.class, "getSomething", int.class, String.class), (7)
handleSupplier, config);
}
@Override
public Something getSomething(int id, String name) {
return (Something) getSomethingInvoker.invoke(id, name);
}
@Override
public Something getIdOne() {
return (Something) getSomethingInvoker.invoke(1, "apple"); (8)
}
}| 1 | The getIdOne method takes no parameters and returns a constant Something object |
| 2 | The extension factory retrieves the metadata for the ExtensionType class. This call is usually done by the extension framework but can be done manually
when implementing the
ExtensionFactory#attach(). |
| 3 | The extension factory returns an implementation of the extension type. |
| 4 | The extension factory requests that the framework returns the implementation as is and not wrap it into extension handlers. |
| 5 | The extension factory adds an extension handler factory that provides the actual implementation. |
| 6 | The extension handler factory only accepts the getSomething method, it does not create an extension handler for getIdOne. |
| 7 | The extension type uses the metadata object to create an extension handler invoker for the getSomething method. This is handled by the custom extension
handler factory. |
| 8 | The getIdOne method now invokes the extension handler for the getSomething method and passes constant values to the
ExtensionHandlerInvoker#invoke() method. |
19. Advanced Topics
19.1. High Availability
Jdbi can be combined with connection pools and high-availability features in your database driver. We’ve used HikariCP in combination with the PgJDBC connection load balancing features with good success.
PGSimpleDataSource ds = new PGSimpleDataSource();
ds.setServerName("host1,host2,host3");
ds.setLoadBalanceHosts(true);
HikariConfig hc = new HikariConfig();
hc.setDataSource(ds);
hc.setMaximumPoolSize(6);
Jdbi jdbi = Jdbi.create(new HikariDataSource(hc)).installPlugin(new PostgresPlugin());Each Jdbi may be backed by a pool of any number of hosts, but the connections should all be alike. Exactly which parameters must stay the same and which may vary depends on your database and driver.
If you want to have two separate pools, for example a read-only set that connects to read replicas
and a smaller pool of writers that go only to a single host, you currently should have separate
Jdbi instances each pointed at a separate DataSource.
19.2. Compiling with Parameter Names
By default, the Java compiler does not write parameter names of constructors and methods to class files. At runtime, using reflection to find parameter names will return values like "arg0", "arg1", etc.
Out of the box, Jdbi uses annotations to name parameters, e.g.:
-
ConstructorMapperuses the@ConstructorPropertiesannotation. -
SQL Object method arguments use the @Bind annotation.
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insert(@Bind("id") long id, @Bind("name") String name);If you compile your code with the -parameters compiler flag, then the need for
these annotations is removed — Jdbi automatically uses the method parameter name:
@SqlUpdate("INSERT INTO users (id, name) VALUES (:id, :name)")
void insert(long id, String name);19.2.1. Maven Setup
Configure the maven-compiler-plugin in your POM:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>19.2.2. IntelliJ IDEA setup
-
File → Settings
-
Build, Execution, Deployment → Compiler → Java Compiler
-
Additional command-line parameters:
-parameters -
Click Apply, then OK.
-
Build → Rebuild Project
19.2.3. Eclipse Setup
-
Window → Preferences
-
Java → Compiler
-
Under "Classfile Generation," check the option "Store information about method parameters (usable via reflection)."
19.3. Working with Generic Types
Jdbi provides utility classes to make it easier to work with Java generic types.
19.3.1. GenericType
GenericType represents a generic type signature that can be passed around in a type-safe way.
Create a generic type reference by instantiating an anonymous inner class:
new GenericType<Optional<String>>() {}This type reference can be passed to any Jdbi method that accepts a
GenericType<T>, e.g.:
List<Optional<String>> middleNames = handle
.select("SELECT middle_name FROM contacts")
.mapTo(new GenericType<Optional<String>>() {})
.list();The GenericType.getType() returns the raw
java.lang.reflect.Type object used
to represent generics in Java.
19.3.2. The GenericTypes helper
GenericTypes provides methods for working with Java generic types signatures.
All methods in GenericTypes operate in terms of java.lang.reflect.Type.
The getErasedType(Type) method accepts a Type and returns the raw Class
for that type, with any generic parameters erased:
Type listOfInteger = new GenericType<List<Integer>>() {}.getType();
GenericTypes.getErasedType(listOfInteger); // => List.class
GenericTypes.getErasedType(String.class); // => String.classThe resolveType(Type, Type) method takes a generic type, and a context type in
which to resolve it.
For example, given the type variable T from Optional<T>:
Type t = Optional.class.getTypeParameters()[0];And given the context type Optional<String>:
Type optionalOfString = new GenericType<Optional<String>>() {}.getType();The resolveType() method answers the question: "what is type T, in the context
of type Optional<String>?"
GenericTypes.resolveType(t, optionalOfString);
// => String.classThis scenario of resolving the first type parameter of some generic supertype is so common that we made a separate method for it:
GenericTypes.findGenericParameter(optionalOfString, Optional.class);
// => Optional.of(String.class)
Type listOfInteger = new GenericType<List<Integer>>() {}.getType();
GenericTypes.findGenericParameter(listOfInteger, Collection.class);
// => Optional.of(Integer.class)Note that this method will return Optional.empty() if the type parameter cannot be resolved, or the types have nothing to do with each other:
GenericTypes.findGenericParameter(optionalOfString, List.class);
// => Optional.empty();19.4. NamedArgumentFinder
The NamedArgumentFinder
interface, as its name suggests, finds arguments by name from some source.
Typically, a single NamedArgumentFinder instance will provide arguments for
several names.
In cases where neither bindBean(), bindFields(), bindMethods(), nor
bindMap() are a good fit, you can implement your own NamedArgumentFinder and
bind that, instead of extracting and binding each argument individually.
Cache cache = ... // e.g. Guava Cache
NamedArgumentFinder cacheFinder = (name, ctx) ->
Optional.ofNullable(cache.getIfPresent(name))
.map(value -> ctx.findArgumentFor(Object.class, value));
stmt.bindNamedArgumentFinder(cacheFinder);
Under the hood, the
SqlStatement.bindBean(),
SqlStatement.bindMethods(),
SqlStatement.bindFields(),
and
SqlStatement.bindMap()
methods are just creating and binding custom implementations of
NamedArgumentFinder for beans, methods, fields, and maps, respectively.
|
19.5. JdbiConfig
Configuration is managed by the ConfigRegistry class. Each Jdbi object that represents a distinct database context (for example, Jdbi itself, a Handle instance, or an attached SqlObject class) has a separate config registry instance.
A context implements the Configurable interface which allows modification of its configuration as well as retrieving the current context’s configuration for use by Jdbi core or extensions.
When a new context is created, it inherits a copy of its parent configuration at the time of creation - further modifications to the original will not affect already created configuration contexts. Configuration context copies happen when creating a Handle from Jdbi, when opening a SqlStatement from the Handle, and when attaching or creating an on-demand extension such as SqlObject.
The configuration itself is stored in implementations of the JdbiConfig interface. Each implementation must adhere to the contract of the interface; in particular it must have a public no-argument constructor that provides useful defaults and an implementation of the JdbiConfig#createCopy method that is invoked when a configuration registry is cloned.
Configuration should be set on a context before that context is used, and not changed later. Some configuration classes may be thread-safe but most are not. Configuration objects should be implemented so that they are cheap to copy, for example the base ones use copy-on-write collections.
Many of Jdbi’s core features, for example argument or mapper registries, are simply implementations of JdbiConfig that store the registered mappings for later use during query execution.
public class ExampleConfig implements JdbiConfig<ExampleConfig> {
private String color;
private int number;
public ExampleConfig() {
color = "purple";
number = 42;
}
private ExampleConfig(ExampleConfig other) {
this.color = other.color;
this.number = other.number;
}
public ExampleConfig setColor(String color) {
this.color = color;
return this;
}
public String getColor() {
return color;
}
public ExampleConfig setNumber(int number) {
this.number = number;
return this;
}
public int getNumber() {
return number;
}
@Override
public ExampleConfig createCopy() {
return new ExampleConfig(this);
}
}19.5.1. Creating a custom JdbiConfig type
-
Create a public class that implements JdbiConfig.
-
Add a public, no-argument constructor
-
Add a private, copy constructor.
-
Implement
createCopy()to call the copy constructor. -
Add config properties, and provide sane defaults for each property.
-
Ensure that all config properties get copied to the new instance in the copy constructor.
-
Override
setConfig(ConfigRegistry)if your config class wants to be able to use other config classes in the registry. E.g. RowMappers registry delegates to ColumnMappers registry, if it does not have a mapper registered for a given type. -
Use that configuration object from other classes that are interested in it.
-
e.g. BeanMapper, FieldMapper, and ConstructorMapper all use the ReflectionMappers config class to keep common configuration.
-
19.6. JdbiPlugin
JdbiPlugin can be used to bundle bulk configuration.
Plugins may be installed explicitly via Jdbi.installPlugin(JdbiPlugin), or
may be installed automagically from the classpath using the ServiceLoader mechanism
via installPlugins().
Jars may provide a file in META-INF/services/org.jdbi.v3.core.spi.JdbiPlugin
containing the fully qualified class name of your plugin.
In general, Jdbi’s separate artifacts each provide a single relevant plugin (e.g. jdbi3-sqlite),
and such modules will be auto-loadable. Modules that provide no (e.g. jdbi3-commons-text)
or multiple (e.g. jdbi3-core) plugins typically will not be.
| The developers encourage you to install plugins explicitly. Code with declared dependencies on the module it uses is more robust to refactoring and provides useful data for static analysis tools about what code is or is not used. |
19.7. StatementContext
The StatementContext class holds the state for all statements. It is a stateful object that should not be shared between threads. It may be used by different threads as long as this happens sequentially.
The statement context object is passed into most user extension points, e.g. RowMapper, ColumnMapper, or CollectorFactory.
The StatementContext is not intended to be extended and extension points should use it to get access to other parts of the system (especially the config registry). They rarely need to make changes to it.
19.8. TemplateEngine
Jdbi uses a TemplateEngine
implementation to render templates into SQL. Template engines take a SQL
template string and the StatementContext as input, and produce a parseable
SQL string as output.
Out of the box, Jdbi is configured to use DefinedAttributeTemplateEngine, which replaces angle-bracked tokens like <name> in SQL statements with
the string value of the named attribute:
String tableName = "customers";
Class<?> entityClass = Customer.class;
handle.createQuery("SELECT <columns> FROM <table>")
.define("table", "customers")
.defineList("columns", "id", "name")
.mapToMap()
.list() // => "SELECT id, name FROM customers"
The defineList method defines a list of elements as the comma-separated
splice of String values of the individual elements. In the above example,
the columns attribute is defined as "id, name".
|
Jdbi supports custom template engines through the TemplateEngine interface. By calling Configurable#setTemplateEngine() method on the Jdbi, Handle, or any SQL statement like Update or Query, the template engine used to render SQL can be changed:
TemplateEngine templateEngine = (template, ctx) -> {
...
};
jdbi.setTemplateEngine(templateEngine);| Jdbi also provides StringTemplateEngine, which renders templates using the StringTemplate library. See StringTemplate 4. |
Template engines interact with the SQL template caching. A template engine may implement the TemplateEngine#parse() methods to create an intermediary representation of a template that can be used to render a template faster. The output of this method will be cached. Depending on the implementation, defined attributes may be resolved at parse time and not at render time.
The most commonly used template engines (DefinedAttributeTemplateEngine and StringTemplateEngine do not support caching).
19.9. SqlParser
After the SQL template has been rendered, Jdbi uses a SqlParser to parse out any named parameters from the SQL statement. This Produces a ParsedSql object, which contains all the information Jdbi needs to bind parameters and execute the SQL statement.
Out of the box, Jdbi is configured to use ColonPrefixSqlParser, which
recognizes colon-prefixed named parameters, e.g. :name.
handle.createUpdate("INSERT INTO characters (id, name) VALUES (:id, :name)")
.bind("id", 1)
.bind("name", "Dolores Abernathy")
.execute();Jdbi also provides HashPrefixSqlParser, which recognizes hash-prefixed
parameters, e.g. #hashtag. Other custom parsers implement the SqlParser
interface.
By calling Configurable#setSqlParser() method on the Jdbi, Handle, or any SQL statement like Update or Query, the parser used to define named arguments can be changed:
handle.setSqlParser(new HashPrefixSqlParser())
.createUpdate("INSERT INTO characters (id, name) VALUES (#id, #name)")
.bind("id", 2)
.bind("name", "Teddy Flood")
.execute();The default parsers recognize any Java identifier and additionally the dot and dash (. and -) as a valid characters in a parameter or attribute name. Even some strange cases like emoji are allowed, although the Jdbi authors encourage appropriate discretion 🧐.
| The default parsers try to ignore parameter-like constructions inside of string literals, since JDBC drivers wouldn’t let you bind parameters there anyway. |
19.10. SqlLogger
The SqlLogger interface
is called before and after executing each statement,
and given the current StatementContext, to log any relevant information desired:
mainly the query in various compilation stages,
attributes and bindings, and important timestamps.
There’s a simple Slf4JSqlLogger implementation that logs all executed statements for debugging.
19.11. ResultProducer
A ResultProducer takes a lazily supplied PreparedStatement and produces a result. The most common producer path, execute(), retrieves the ResultSet over the query results and then uses a ResultSetScanner or higher level mapper to produce results.
An example alternate use is to just return the number of rows modified, as in an UPDATE or INSERT statement:
public static ResultProducer<Integer> returningUpdateCount() {
return (statementSupplier, ctx) -> {
try {
return statementSupplier.get().getUpdateCount();
} finally {
ctx.close();
}
};
}If you acquire the lazy statement, you are responsible for ensuring that the context is closed eventually to release database resources.
Most users will not need to implement the ResultProducer interface.
19.12. Jdbi SQL object code generator
Jdbi includes an experimental SqlObject code generator. If you
include the jdbi3-generator artifact as an annotation processor and
annotate your SqlObject definitions with @GenerateSqlObject, the
generator will produce an implementing class and avoids using
Java proxy instances.
This may be useful for graal-native compilation.
19.13. HandleCallbackDecorator
Jdbi allows specifying a decorator that can be applied to all callbacks passed to useHandle, withHandle, useTransaction, or inTransaction. This is for use-cases where you need to perform an action on all callbacks used in Jdbi. For instance, you might want to have global retries whether a transaction is used or not. Jdbi already provides retry handlers for transactions, but you might want to retry auto-commit (non-transaction) queries as well. E.g.
public class ExampleJdbiPlugin
implements JdbiPlugin, HandleCallbackDecorator
{
@Override
public void customizeJdbi(Jdbi jdbi)
{
jdbi.setHandleCallbackDecorator(this);
}
@Override
public <R, X extends Exception> HandleCallback<R, X> decorate(HandleCallback<R, X> callback)
{
return handle -> {
try {
if (handle.getConnection().getAutoCommit()) {
// do retries for auto-commit
return withRetry(handle, callback);
}
}
catch (SQLException e) {
throw new ConnectionException(e);
}
// all others get standard behavior
return callback.withHandle(handle);
};
}
private <R, X extends Exception> R withRetry(Handle handle, HandleCallback<R, X> callback)
throws X
{
while (true) {
try {
return callback.withHandle(handle);
}
catch (Exception last) {
// custom auto-commit retry behavior goes here
}
}
}
}20. Appendix
20.1. Best Practices
-
Test your SQL Objects (DAOs) against real databases when possible. Jdbi tries to be defensive and fail eagerly when you hold it wrong.
-
Use the
-parameterscompiler flag to avoid all those@Bind("foo") String fooredundant qualifiers in SQL Object method parameters. See Compiling with Parameter Names. -
Use a profiler! The true root cause of performance problems can often be a surprise. Measure first, then tune for performance. And then measure again to be sure it made a difference.
-
Don’t forget to bring a towel!
20.3. Related Projects
Embedded Postgres makes testing against a real database quick and easy.
dropwizard-jdbi3 provides integration with DropWizard.
metrics-jdbi3 instruments using DropWizard-Metrics to emit statement timing statistics.
Do you know of a project related to Jdbi? Send us an issue, and we’ll add a link here!
20.4. Upgrading from v2 to v3
Already using Jdbi v2?
Here’s a quick summary of differences to help you upgrade:
General:
-
Maven artifacts renamed and split out:
-
Old:
org.jdbi:jdbi -
New:
org.jdbi:jdbi3-core,org.jdbi:jdbi3-sqlobject, etc. -
Root package renamed:
org.skife.jdbi.v2→org.jdbi.v3
Core API:
-
DBI,IDBI→ Jdbi-
Instantiate with
Jdbi.create()factory methods instead of constructors.
-
-
DBIException→JdbiException -
Handle.select(String, …)now returns a Query for further method chaining, instead of a List<Map<String, Object>>. CallHandle.select(sql, …).mapToMap().list()for the same effect as v2. -
Handle.insert()andHandle.update()have been coalesced intoHandle.execute(). -
ArgumentFactoryis no longer generic. -
AbstractArgumentFactoryis a generic implementation ofArgumentFactoryfor factories that handle a single argument type. -
Argument and mapper factories now operate in terms of
java.lang.reflect.Typeinstead ofjava.lang.Class. This allows Jdbi to handle arguments and mappers for generic types. -
Argument and mapper factories now have a single
build()method that returns an Optional, instead of separateaccepts()andbuild()methods. -
ResultSetMapper→ RowMapper. The row index parameter was also removed fromRowMapper--the current row number can be retrieved directly from theResultSet. -
ResultColumnMapper→ ColumnMapper -
ResultSetMapperFactory→ RowMapperFactory -
ResultColumnMapperFactory→ ColumnMapperFactory -
Query no longer maps to
Map<String, Object>by default. CallQuery.mapToMap(),.mapToBean(type),.map(mapper)or.mapTo(type). -
ResultBearing<T>was refactored intoResultBearing(no generic parameter) andResultIterable<T>. Call.mapTo(type)to get aResultIterable<T>. -
TransactionConsumerandTransactionCallbackonly take a Handle now—theTransactionStatusargument is removed. Just rollback the handle now. -
TransactionStatusclass removed. -
CallbackFailedExceptionclass removed. The functional interfaces likeHandleConsumer,HandleCallback,TransactionCallback, etc. can now throw any exception type. Methods likeJdbi.inTransactionthat take these callbacks use exception transparency to throw only the exception thrown by the callback. If your callback throws no checked exceptions, you don’t need a try/catch block. -
StatementLocatorinterface removed from core. All core statements expect to receive the actual SQL string now. A similar concept,SqlLocatorwas added but is specific to SQL Object. -
StatementRewriterrefactored into TemplateEngine, and SqlParser. -
StringTemplate no longer required to process
<name>-style tokens in SQL. -
Custom SqlParser implementations must now provide a way to transform raw parameter names to names that will be properly parsed out as named params.
SQL Object API:
-
SQL Object support is not installed by default. It must be added as a separate dependency, and the plugin installed into the Jdbi object:
Jdbi jdbi = Jdbi.create(...);
jdbi.installPlugin(new SqlObjectPlugin());-
SQL Object types in v3 must be public interfaces—no classes. Method return types must likewise be public. This is due to SQL Object implementation switching from CGLIB to
java.lang.reflect.Proxy, which only supports interfaces. -
GetHandle→SqlObject -
SqlLocatorreplacesStatementLocator, and only applies to SQL Objects. -
@RegisterMapperdivided into @RegisterRowMapper and @RegisterColumnMapper. -
@Bind annotations on SQL Object method parameters can be made optional, by compiling your code with the
-parameterscompiler flag enabled. -
@BindIn→ @BindList, and no longer requires StringTemplate -
On-demand SQL objects don’t play well with methods that return
IterableorFluentIterable. On-demand objects strictly close the handle after each method call, and no longer "hold the door open" for you to finish consuming the interable as they did in v2. This forecloses a major source of connection leaks. -
SQL Objects are no longer closeable — they are either on-demand, or their lifecycle is tied to the lifecycle of the Handle they are attached to.
-
@BindAnnotationmeta-annotation removed. Use@SqlStatementCustomizingAnnotationinstead. -
@SingleValueResult→ @SingleValue. The annotation may be used for method return types, or on @SqlBatch parameters.